
- 什么是深度学习?
- 深度学习的前沿研究与应用
- 深度学习和传统算法在缺陷检测应用中的特点
- 深度学习训练工具VisionTrain1.4.1功能更新说明
- 模型优化方法---通用基础篇
- 模型优化方法---VM算法平台预测篇
- 模型优化方法---VisionTrain训练篇
- 模型优化方法---预测耗时篇
- 深度学习小工具之快速图像分割
- 深度学习小工具之标签转化工具
- 深度学习小工具之图像名称、标签文件内容修改工具
- 训练误差与泛化误差的关系
- 训练过程中对于误差值的理解
- 基本图像增强算法对深度学习模型结果的影响
- 使用VM深度学习功能实现模型训练与图像检索功能
- 智能相机-深度学习OCR训练及优化指南
- 一种提升OCR模型识别率的优化方法
- 根据实际需求找到最优方案-OCR识别篇
- 多分类分割任务下实现指定类别的阈值调整
- 多分类分割任务下的标注问题及解决思路
- 图像分割标注训练经验分享
- 基于VM界面层的多类别缺陷统计方案
- VM深度学习OCR项目经验分享
- 【VM集成开源AI】深度学习算子模块封装
- 深度学习推理耗时波动现象的解决方法
- 【共享学习】关于深度学习显卡推理那些事儿
- VM7100深度学习检测温度传感器焊点,裸针,锡珠,超盘,
- 深度学习缺陷检测项目经验分享
- 深度学习基础介绍
- 深度学习VS注册学习
使用VM深度学习功能实现模型训练与图像检索功能
- 0
- 7
- 分享
- 2022-02-15 10:07
本文主要介绍如何使用VM深度学习工具自己训练模型实现图像检索功能。
1. 图像检索原理
图像检索主要分为图像的表示学习和分类器注册两部分。图像的表示学习就是通过构建网络模型实现图像的特征表示,分类器注册就是将表示学习网络输出的图像特征向量输入分类器进行分类器注册。使用VM实现图像检索前也需要进行模型训练和分类器注册。
图像检索和图像分类的区别:图像分类是直接训练一个固定类别数的分类器模型;图像检索是训练一个图像表示模型,然后针对不同的检索库注册不同的分类器模型,从而避免了针对不同检索库需要训练不同网络模型的麻烦,提升网络模型的泛化能力。
2. 基于VM的图像检索方法
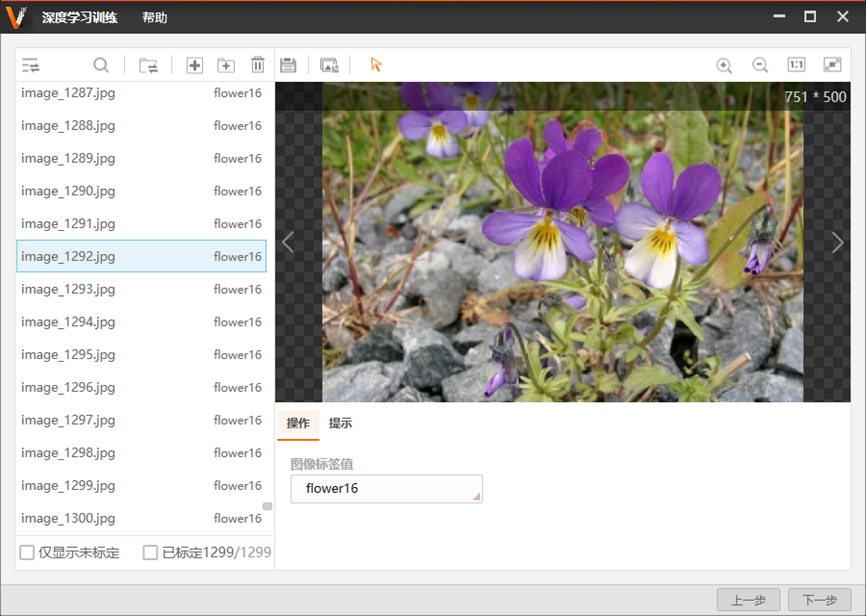
2.1 打标签
可以使用VMTrain1.4.0来进行数据集打标签工作,添加图片是对单张图片进行打标,添加文件夹是对多张图片批量打标签。打标签的结果如图所显示。
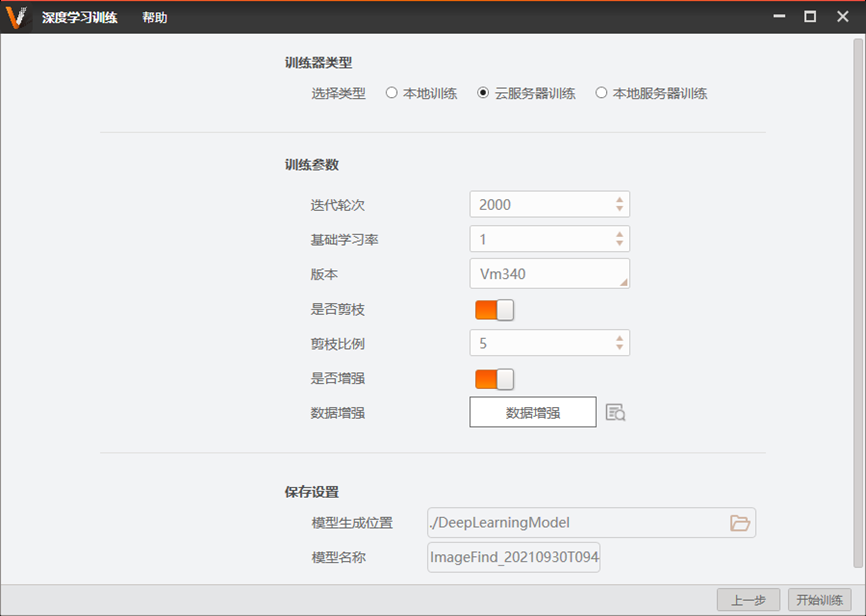
2.2 模型训练
模型训练有三种环境可以选择:本地训练(需要支持深度学习加速的NVIDIA显卡和CUDA环境)、云服务器训练和本地服务器训练。训练参数:训练迭代次数(可以根据数据量来调整)、基础学习率(可以控制模型的收敛速度)、版本、剪枝比例(模型压缩手段,可以根据模型性能和精度来权衡调整)、数据增强(数据集扩充手段,用于丰富数据量,防止过拟合)。参数设置完毕,点击开始训练。训练结束在指定为文件夹下会生成bin文件(模型权重文件)。
2.3 注册图像
在VM中使用DL图像检索模块中的Gallery管理中的注册图像按钮进行图像注册,可以单张图像注册,也可以按文件夹注册(可以针对不同的检索库注册不同的Gallery,执行时按需要加载gall文件)。
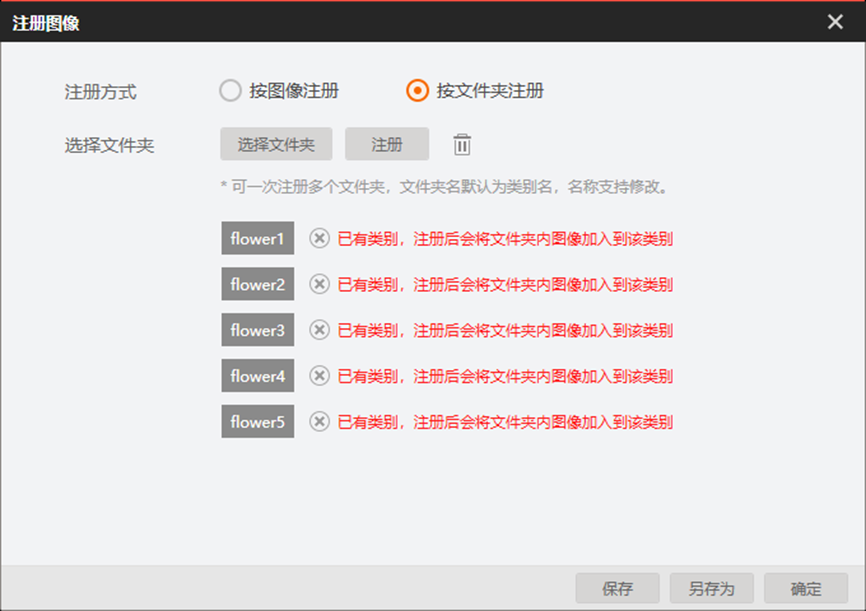
2.4 图像检索
图像检索方案如图所示,主要使用DL图像检索模块进行图像检索。
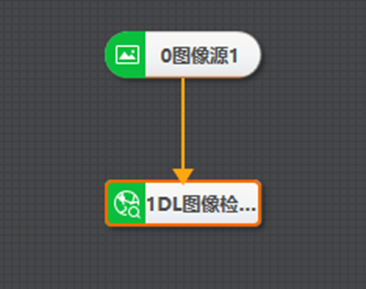
参数配置:需要加载训练好的模型文件(VisionTrain训练得到的bin文件)和注册好的Gallery文件(gall文件)。

2.5 检索结果

版权声明:本文为V社区用户原创内容,转载时必须标注文章的来源(V社区),文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件至:v-club@hikrobotics.com 进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容。
评论请先登录 登录
全部评论 7



2.1 打标签
可以使用VMTrain1.4.0来进行数据集打标签工作,添加图片是对单张图片进行打标,添加文件夹是对多张图片批量打标签。打标签的结果如图所显示。
2022-02-26 16:50:07 未知地区
回复
0
- 1

所属专题
相关阅读
 【技术分享】VM实现状态机2026-04-17
【技术分享】VM实现状态机2026-04-17 VisionMaster4.4(官网最新版)BUG--运行界面设计时,控件无法复制粘贴2026-04-16
VisionMaster4.4(官网最新版)BUG--运行界面设计时,控件无法复制粘贴2026-04-16- 移动机器人技术分享-26年4月2026-04-17
 巅峰对决启幕!第四届启智杯机器智能大赛决赛入围名单暨优胜奖项公告2026-04-24
巅峰对决启幕!第四届启智杯机器智能大赛决赛入围名单暨优胜奖项公告2026-04-24
 浙公网安备 33010802013223号
浙公网安备 33010802013223号