



- 什么是深度学习?
- 深度学习的前沿研究与应用
- 深度学习和传统算法在缺陷检测应用中的特点
- 深度学习训练工具VisionTrain1.4.1功能更新说明
- 模型优化方法---通用基础篇
- 模型优化方法---VM算法平台预测篇
- 模型优化方法---VisionTrain训练篇
- 模型优化方法---预测耗时篇
- 深度学习小工具之快速图像分割
- 深度学习小工具之标签转化工具
- 深度学习小工具之图像名称、标签文件内容修改工具
- 训练误差与泛化误差的关系
- 训练过程中对于误差值的理解
- 基本图像增强算法对深度学习模型结果的影响
- 使用VM深度学习功能实现模型训练与图像检索功能
- 智能相机-深度学习OCR训练及优化指南
- 一种提升OCR模型识别率的优化方法
- 根据实际需求找到最优方案-OCR识别篇
- 多分类分割任务下实现指定类别的阈值调整
- 多分类分割任务下的标注问题及解决思路
- 图像分割标注训练经验分享
- 基于VM界面层的多类别缺陷统计方案
- VM深度学习OCR项目经验分享
- 【VM集成开源AI】深度学习算子模块封装
- 深度学习推理耗时波动现象的解决方法
- 【共享学习】关于深度学习显卡推理那些事儿
- VM7100深度学习检测温度传感器焊点,裸针,锡珠,超盘,
- 深度学习缺陷检测项目经验分享
- 深度学习基础介绍
- 深度学习VS注册学习
模型优化方法---通用基础篇
- 0
- 2
- 分享
- 2022-05-19 20:39
本文列举了深度学习项目过程中,需要注意的基础要点,通常离不开样本量、标注规范、成像质量以及与项目适应的训练算法。
前面分别针对模型优化方法,列举了关于VM算法平台和VisionTrain下的一些操作细节。
而在这些进阶操作之前,应当把握好问题初衷,俗话说经济基础决定上层建筑,那么下面四大要点,既是深度学习模型性能的影响因子,又是关键要素。
1.样本量
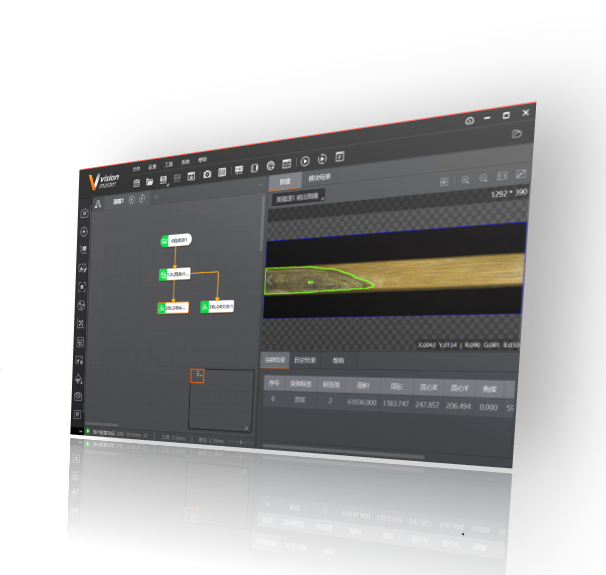
- 一个精度高的模型需要一定量的训练样本,不同的训练类型和不同的目标形态,会影响到模型的检出能力,因此需要扩充样本来提高鲁棒性。在VT中通过添加图片,或者添加文件夹的方式来增加训练集样本。

- 在项目的评估验证期,针对小体量训练集,应增大迭代次数。关于训练参数的设置,可参考对应的训练说明手册。
- 凡是小样本下抛出的模型问题,不能说明算法的优劣性,应当在评估完毕后,选择扩充训练集样本量,重新设置参数训练,再去考虑进阶的优化操作,或是重新评估算法能力。
2.标注规范
1)主要表现在图像分割的标注上,经常会出现下图标注情况:

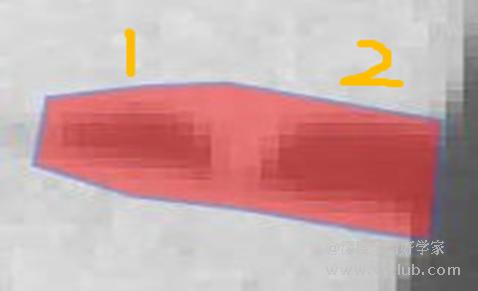
- 图像分割是识别目标轮廓的算法,在标注时应尽量逐像素标定,并贴近缺陷的形状和方向,减少非缺陷特征的干扰。若缺陷1和缺陷2靠的较近,应当分开进行标定,而不是标为一处缺陷,尤其是多分类任务下
- 完整的标定所有规定好的缺陷类型,下图右下角黑点为漏标情况

- 裂缝等比较细的缺陷需要标定稍粗一点,每个缺陷都会有灰度渐变区,应当一并包含进来。同时也不能将其他缺陷特征也包含进来(下图为多分类情况)

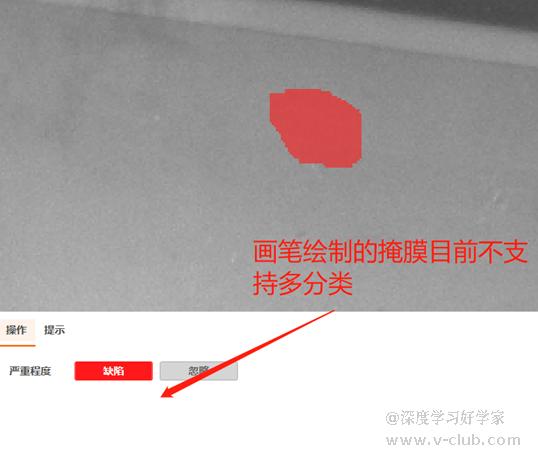
- 注意,图像分割的画笔工具是不支持赋予缺陷类别名的,也就是说当项目需要同步做缺陷定位和分类时,画笔工具首先要排除掉。而大多数的缺陷都是不规则的,矩形和圆形标注工具则显得较为局限,建议默认用多边形工具。
- 对于图像分割的标注,在以上标注规范基础上,如果需要做分类,则需保证类别之间特征差异大,类别内特征差异小,类别数尽可能少的原则,不应以目标出现区域或生成原因划分缺陷类别。下面的图例在模型优化方法中有提到过,两个缺陷类别应合并:


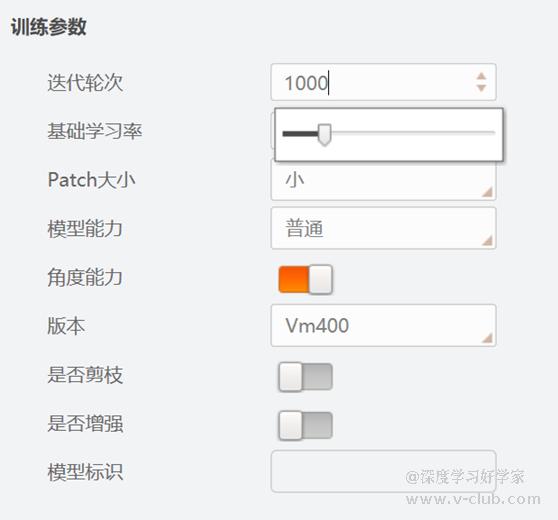
2)若项目是需要检测目标位置的(目标检测),或者检测带角度的字符行位置时(文本行定位),通常使用矩形框标注,而矩形框的朝向应以下图为例:

- 同时,案例图为文本行定位标注,因此两端需留半个字符的空间,同时在训练参数中打开朝向按钮:
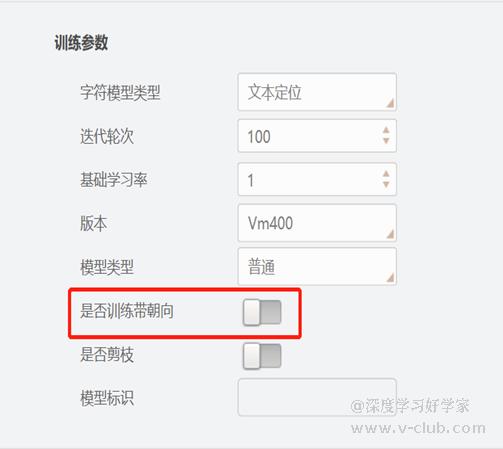
- 如果是目标检测,则需要打开角度按钮:
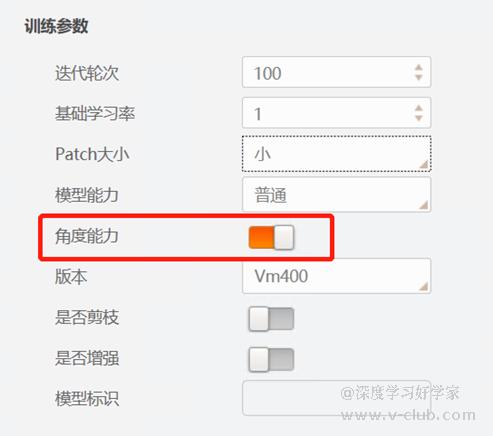
3.成像质量
如下图:
- 例1:调整打光方式,保证目标轮廓的成像清晰,比如选择与特征颜色相近的光源照射,以打亮相近色。

- 例2:使目标对焦,或更换高分辨率镜头,使目标拥有更多的像素点,以保留特征信息。

4.选择与项目合适的训练任务
不同深度学习算法的适用范围可参考训练说明文档。
- 例1:对极小目标的检出任务,使用了目标检测模型,显然是不科学的,目标检测在大patch高精度情况下,检出缺陷与背景占比最小在1.31%,小缺陷的检出建议使用图像分割模型。

- 例2:需要定位到不同类别的目标,此任务应选择目标检测模型而不是图像分类,图像分类又成为全图分类,并不会输出预测的box位置。
- 例3:在项目过程中需要不断增添新类别,则应选择图像检索模型,通过注册新类的gallery来实现。
- 例4:字符串不在同一水平行的情况,应使用单字符识别,而不是文本行定位+文本行识别,文本行定位目前虽然支持全范围角度,但当各字符位置不一时,使用文本行将会包围住背景特征,在具有多字符或高噪点的项目中极易产生混扰。如下图的圆环字符及弯曲字符。


- 例5:实例分割即语义分割与目标检测的结合,通常使用在需要同时检出目标轮廓以及同类目标下不同个体的区分,比如针对叠件的检测。

- 例6:当检出对象为标准logo图案时,可以考虑使用异常检测,或者直接使用VM4.2新推出的无监督模式,对收集的OK图做统一导入和训练即可。当然,如果有充足的NG样本,直接使用图像分割是最具精度的训练方式,只是需要投入标注成本。但根据VisionTrain1.4.2现有的功能来看,目标检测已集成有预标注功能,相信图像分割的预标注也应该会在后续版本推出。
从更深层次来看,以上的操作实际上正是各种数据清洗的过程,目的是为了让数据分布更加科学,使卷积层权重在反馈中更新时,能朝着理想方向快速找到极值。
版权声明:本文为V社区用户原创内容,转载时必须标注文章的来源(V社区),文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件至:v-club@hikrobotics.com 进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容。
评论请先登录 登录

所属专题
相关阅读
 文章专题-【开发有道系列】惊艳上线2026-01-26
文章专题-【开发有道系列】惊艳上线2026-01-26 3D对位贴合案例(RobotPilot22X)2026-01-06
3D对位贴合案例(RobotPilot22X)2026-01-06 V社区四周年寻宝挑战进阶版:荣誉之路正式开启!2026-01-05
V社区四周年寻宝挑战进阶版:荣誉之路正式开启!2026-01-05 continue扩展传参配置2026-01-05
continue扩展传参配置2026-01-05- 光伏行业拉晶工艺及配套设备经验分享2026-01-26
 浙公网安备 33010802013223号
浙公网安备 33010802013223号