



- 什么是深度学习?
- 深度学习的前沿研究与应用
- 深度学习和传统算法在缺陷检测应用中的特点
- 深度学习训练工具VisionTrain1.4.1功能更新说明
- 模型优化方法---通用基础篇
- 模型优化方法---VM算法平台预测篇
- 模型优化方法---VisionTrain训练篇
- 模型优化方法---预测耗时篇
- 深度学习小工具之快速图像分割
- 深度学习小工具之标签转化工具
- 深度学习小工具之图像名称、标签文件内容修改工具
- 训练误差与泛化误差的关系
- 训练过程中对于误差值的理解
- 基本图像增强算法对深度学习模型结果的影响
- 使用VM深度学习功能实现模型训练与图像检索功能
- 智能相机-深度学习OCR训练及优化指南
- 一种提升OCR模型识别率的优化方法
- 根据实际需求找到最优方案-OCR识别篇
- 多分类分割任务下实现指定类别的阈值调整
- 多分类分割任务下的标注问题及解决思路
- 图像分割标注训练经验分享
- 基于VM界面层的多类别缺陷统计方案
- VM深度学习OCR项目经验分享
- 【VM集成开源AI】深度学习算子模块封装
- 深度学习推理耗时波动现象的解决方法
- 【共享学习】关于深度学习显卡推理那些事儿
- VM7100深度学习检测温度传感器焊点,裸针,锡珠,超盘,
- 深度学习缺陷检测项目经验分享
- 深度学习基础介绍
- 深度学习VS注册学习
训练过程中对于误差值的理解
- 0
- 0
- 分享
- 2022-09-01 20:09
本文简要说明了误差值可能存在的理解误区及其潜在意义
在训练深度学习模型的过程中,通常会有一条误差曲线,代表当前样本标注值与预测值的偏差。如样本数据一致性较好,标注也比较科学,我们通常看到的loss值会在迭代次数较小的情况下迅速降低,甚至会低到0-0.1的范围内,此时是否可以断定此模型---它训练“成功”了呢。
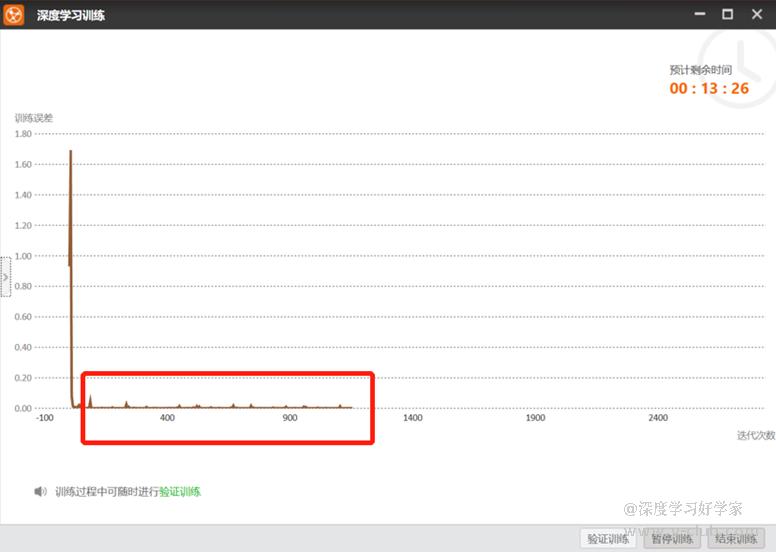
当看到训练误差到0后,我们会直觉的认为,该模型在训练集上验证的准确率为100%,因此选择提前结束训练。实际上,曲线上更新的参数是每个批次(batch)样本下的误差值,同时也做了归一化,看似没有波动,归一化前的误差值还是非常明显的,并不能代表整体样本的误差值。为什么要做归一化?这个操作能降低反向传播的梯度,更有利于数据分布,快速找到期望最优解。而结束训练界面的训练误差值指的是总迭代次数(iteration)下的平均误差,即:
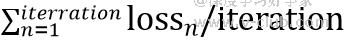
因此即便是0,也是因为分母过大近似为0,在训练集上验证仍可能会有误判,建议等待训练结束,可以在训练中途另存一版模型,根据VM上模型在数据集中的表现来评判是否应该继续迭代。插句题外话,作为使用者,VisionTrain若能实时更新召回率,PR曲线或F1参数,甚至可以将当前模型性能下误判的样本罗列,便于直观了解模型在训练集下的准确率,以节约验证和纠错的时间成本,这样会更利于日常使用。
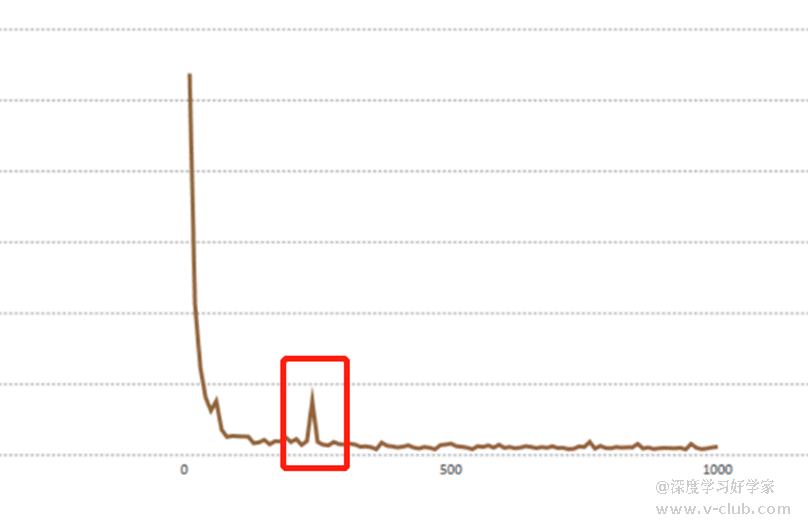
那么训练期间的loss曲线能提示我们什么信息呢?如下图红色框(此处为低迭代次数),我们可能会在迭代过程中,会出现loss激增的情况,特别是高迭代次数,这代表训练集数据中有分错类的,或者标注位置偏差过大,标注策略不一致等现象,以致于影响了学习方向,据此可以暂停训练,回到上一步对标注做复核和修正,正确标注方法可参考本人主页下"模型优化方法"系列。
如上所述,训练误差可以在一定角度上证明模型在训练样本上的学习程度,若需反映整体准确率则要将模型在数据中实际预测一遍。而讨论到模型训练是否成功,也必须要关注泛化误差,即模型在海量测试集内的实际准确率,也是一种期望误差,它会受到各类因素的影响,误差拟合问题我们下篇再见。
版权声明:本文为V社区用户原创内容,转载时必须标注文章的来源(V社区),文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件至:v-club@hikrobotics.com 进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容。
上一篇
下一篇
评论请先登录 登录
全部评论 0

所属专题
相关阅读
 文章专题-【开发有道系列】惊艳上线2026-01-26
文章专题-【开发有道系列】惊艳上线2026-01-26 3D对位贴合案例(RobotPilot22X)2026-01-06
3D对位贴合案例(RobotPilot22X)2026-01-06 V社区四周年寻宝挑战进阶版:荣誉之路正式开启!2026-01-05
V社区四周年寻宝挑战进阶版:荣誉之路正式开启!2026-01-05 continue扩展传参配置2026-01-05
continue扩展传参配置2026-01-05- 光伏行业拉晶工艺及配套设备经验分享2026-01-26
 浙公网安备 33010802013223号
浙公网安备 33010802013223号