工业缺陷检测,你只需要多模态大模型,零训练,直接检测
- 0
- 8
- 分享
- 2026-02-02 19:05
摘要:一种新型缺陷检测方法仅需1-3个正样本即可实现100%检出率,适用于药丸、汽水瓶口、玻璃器等多种产品的缺陷检测。该方法无需标注和训练,相比YOLO、CNN等传统算法优势显著,大大简化了开发流程。虽然该方法提高了检测效率,但也可能减少对专业算法开发人员的需求。
先直接看图吧。
药丸缺陷:只用了3个正样本。
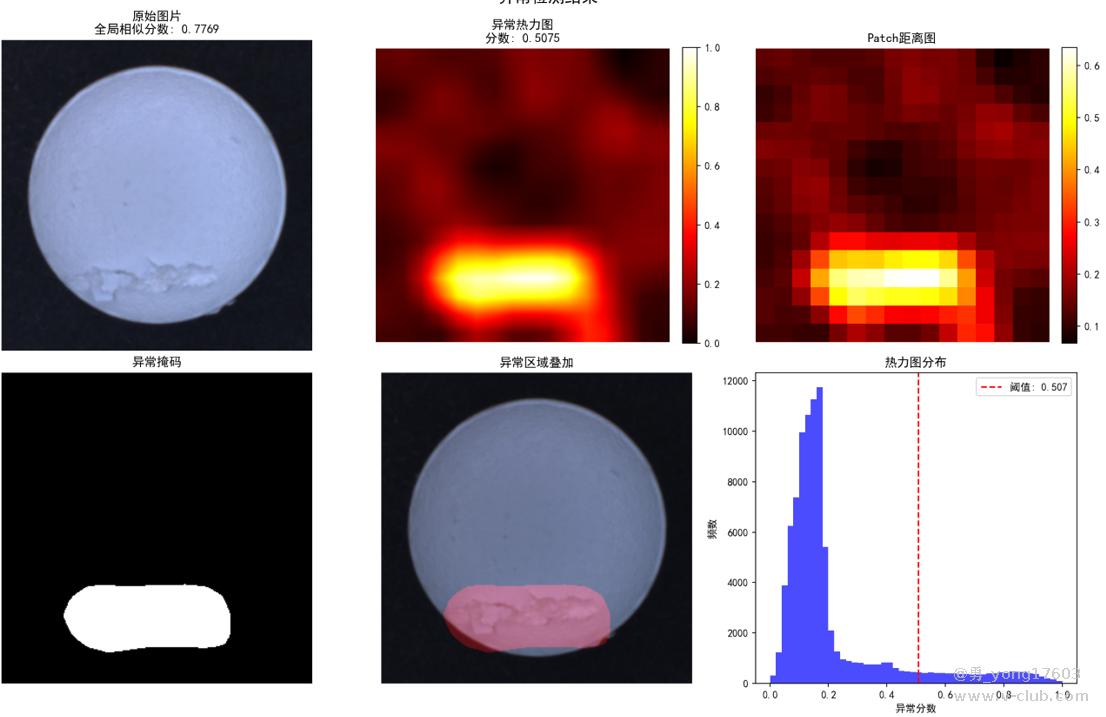
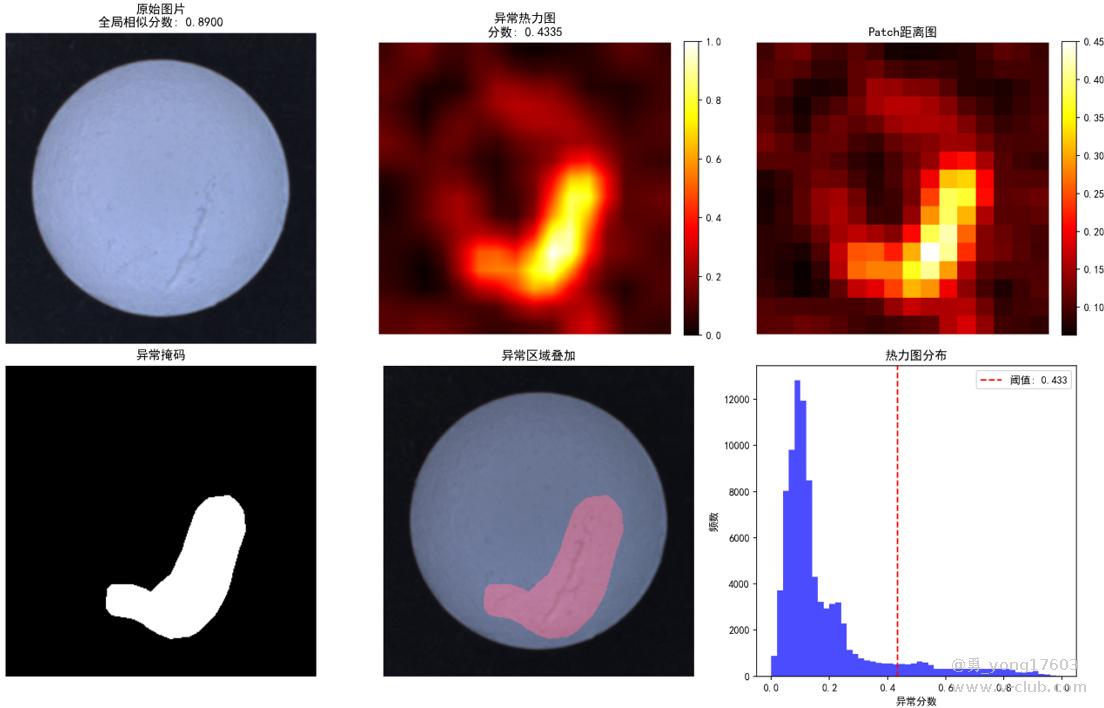
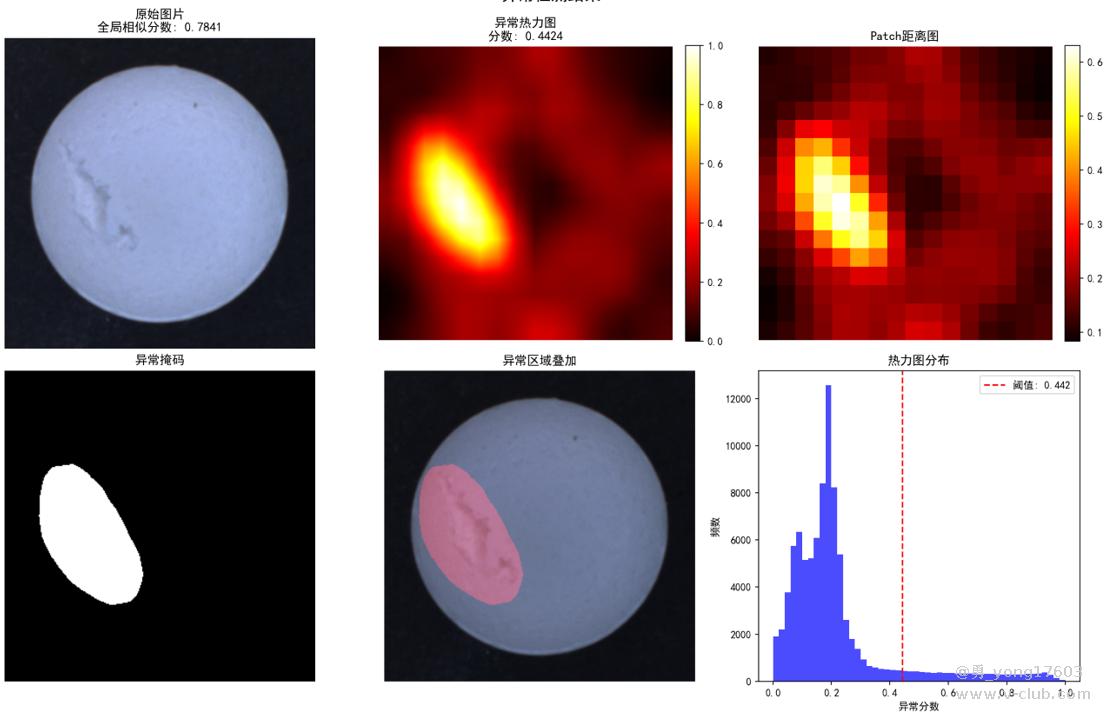
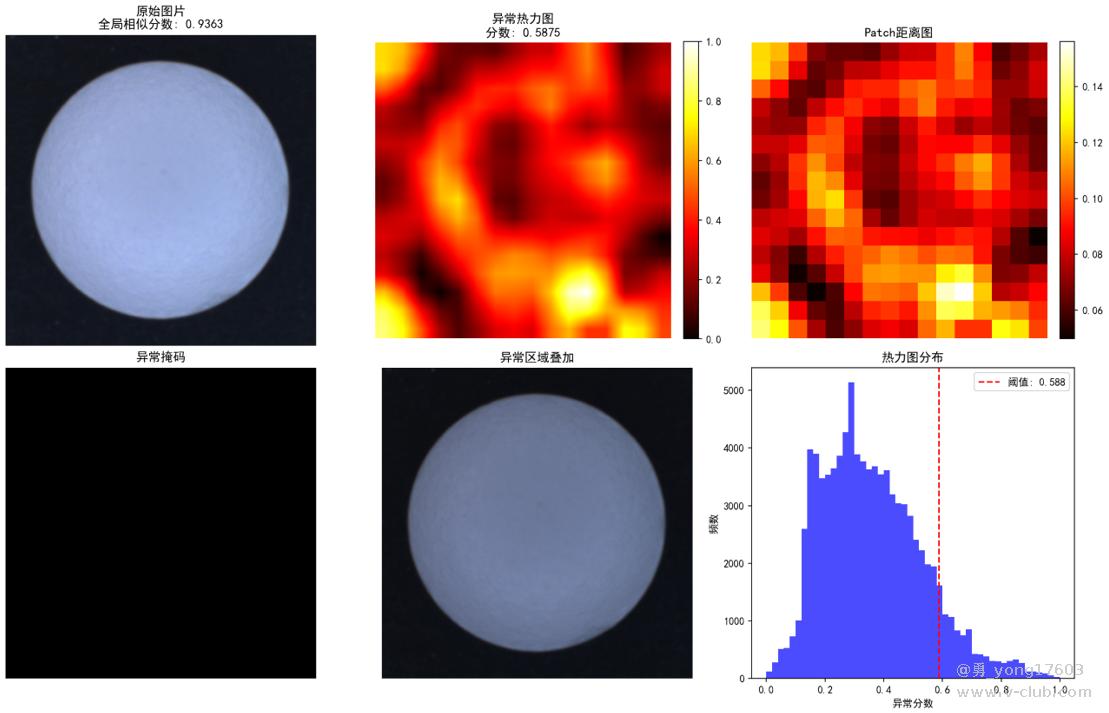
还有,汽水瓶口: 也是只用了3个正样本
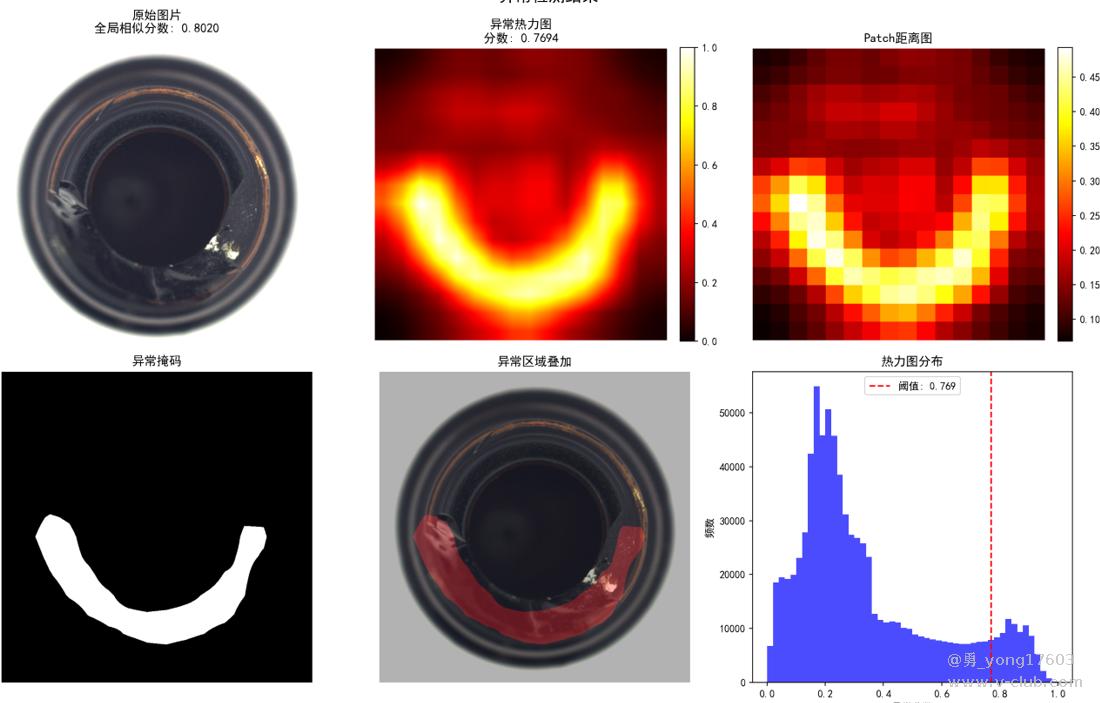
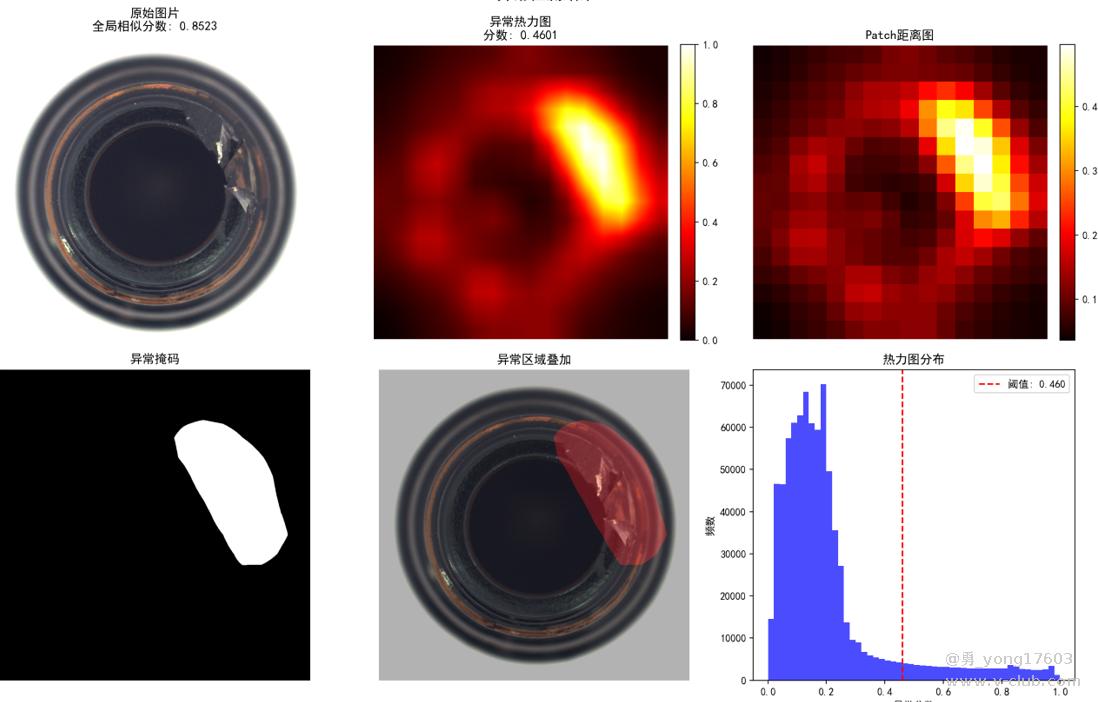
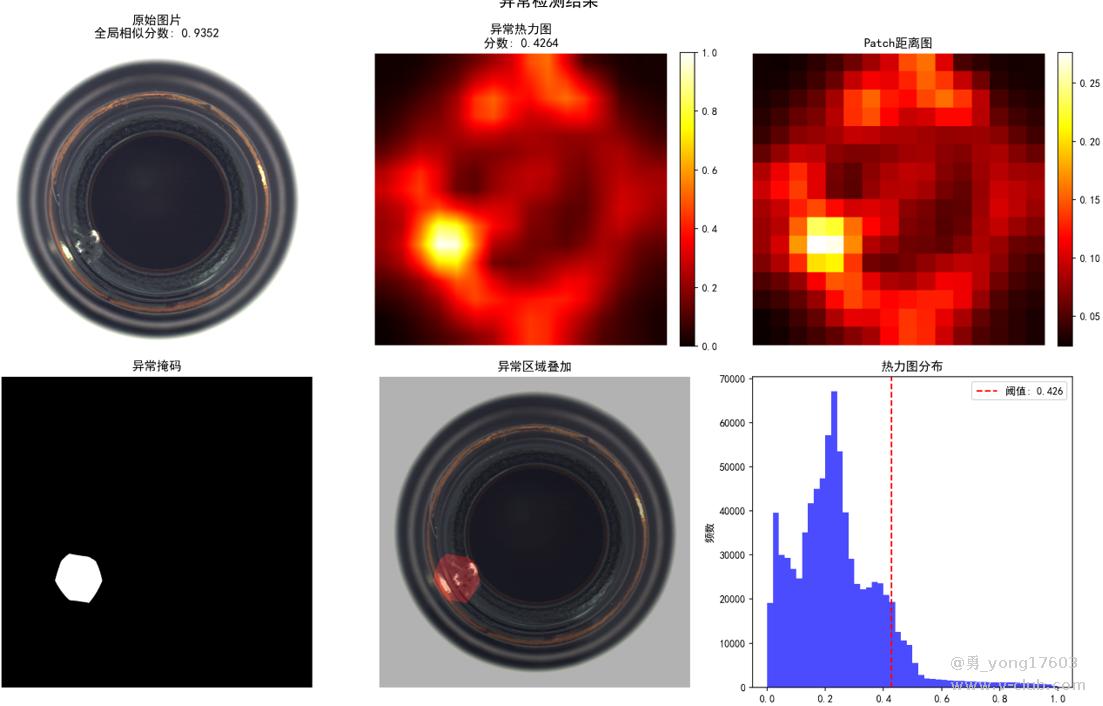
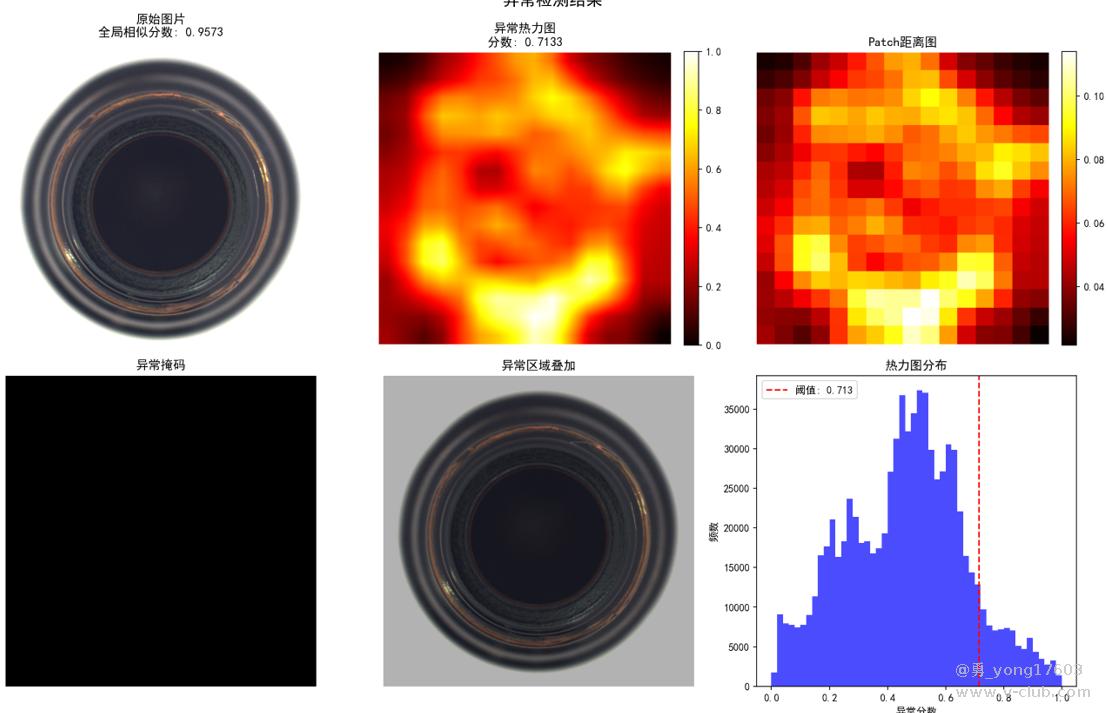
这是 玻璃器瓶口:只用了一个正样本
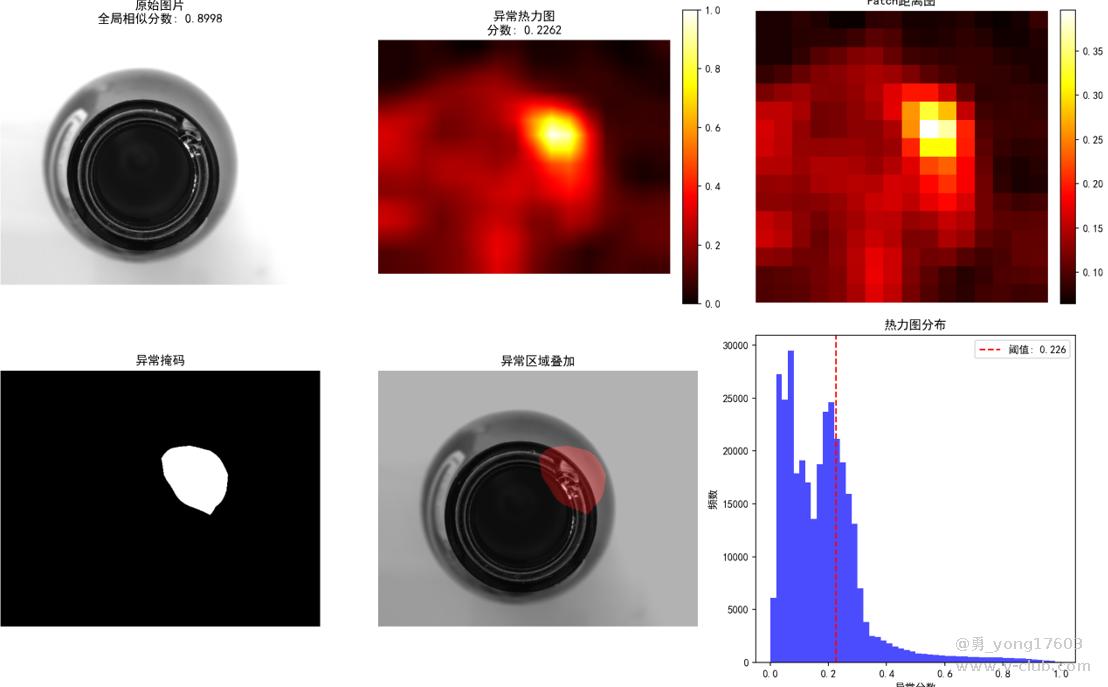
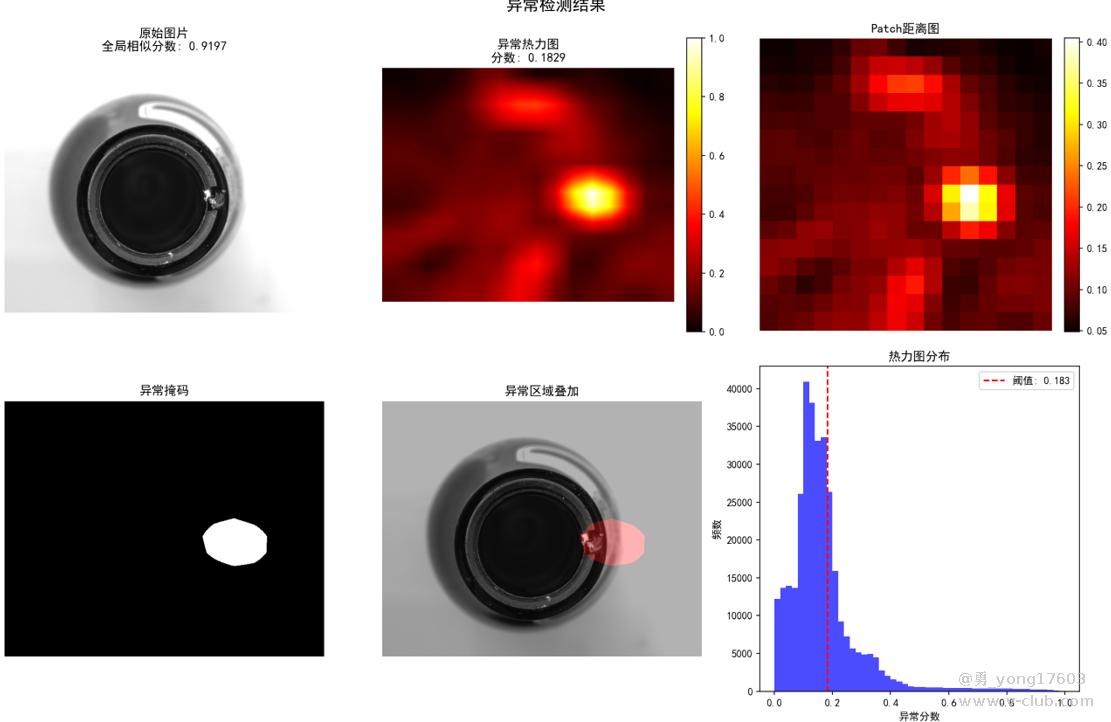
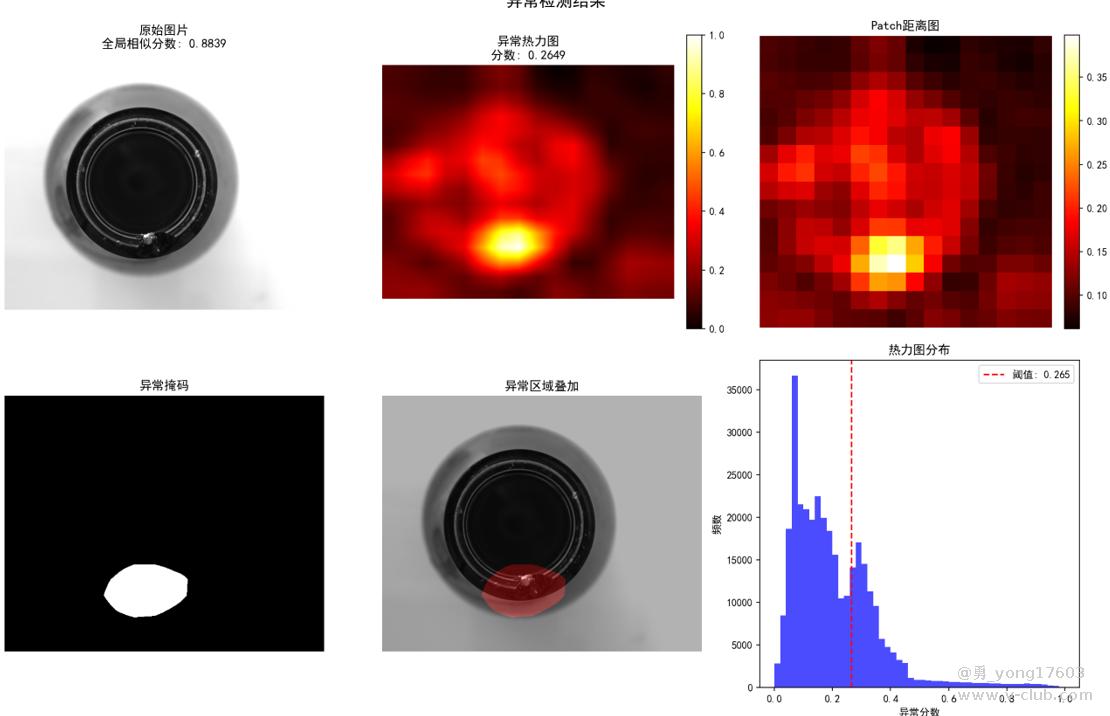
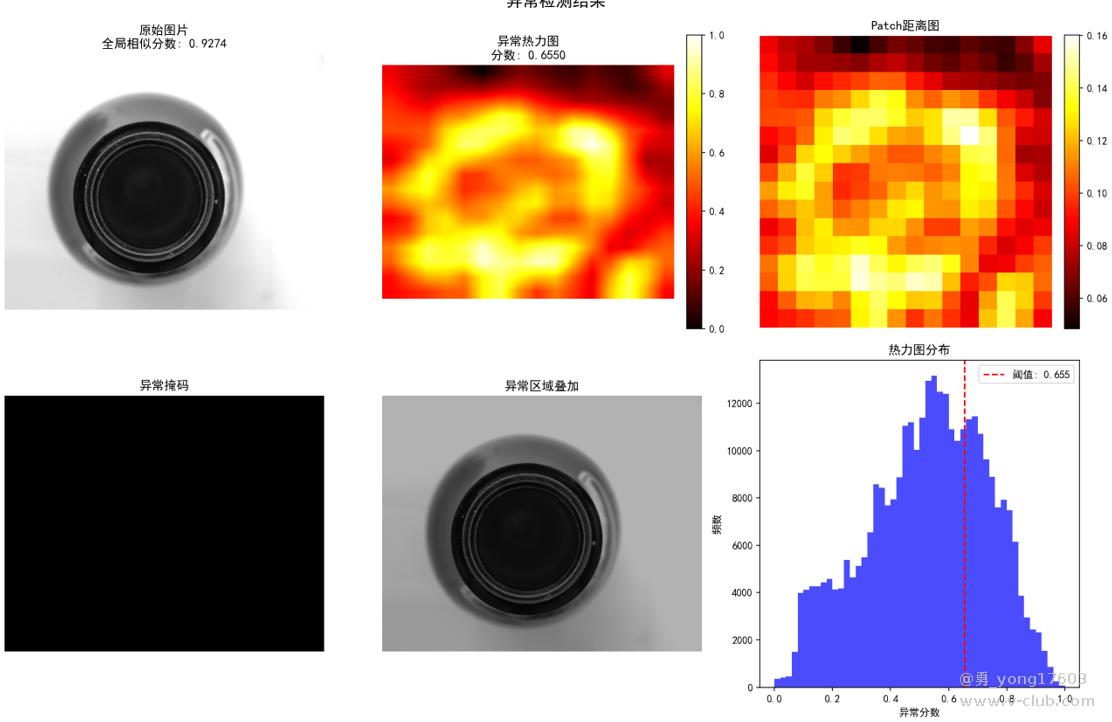
饼干: 用了3个正样本
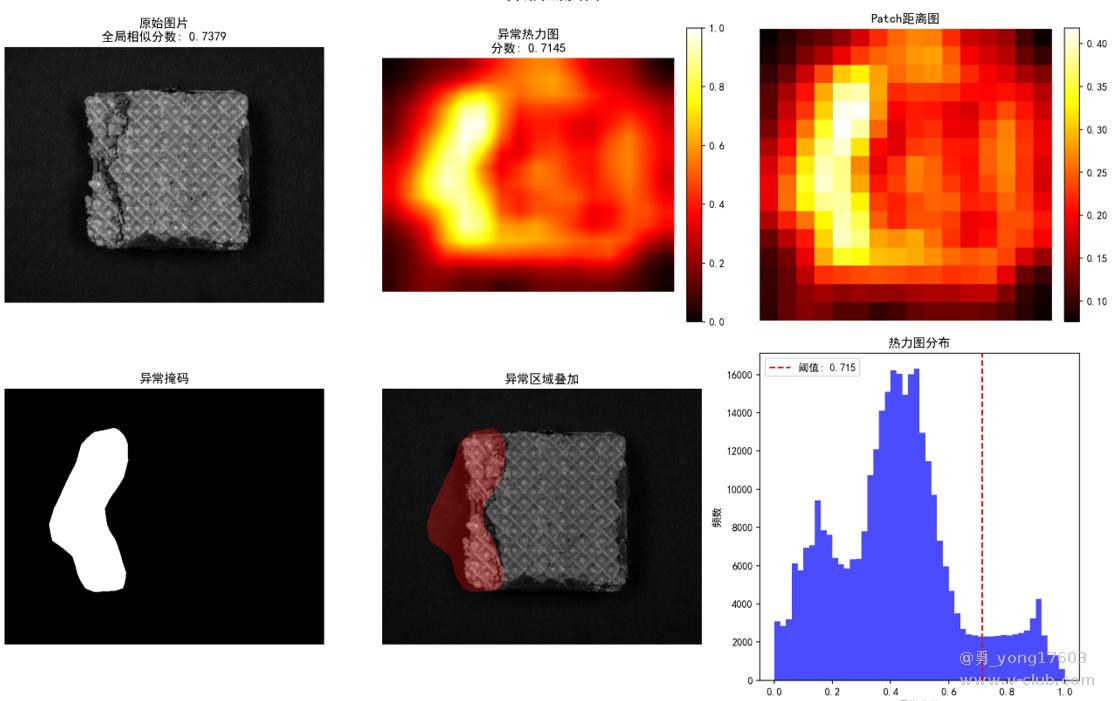
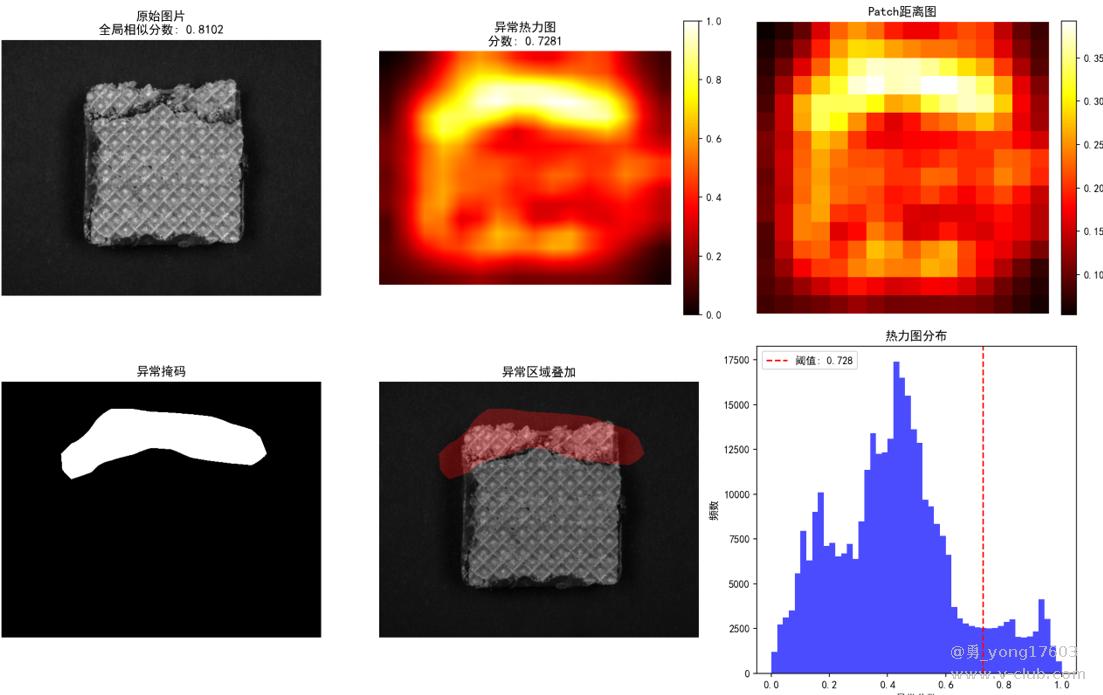
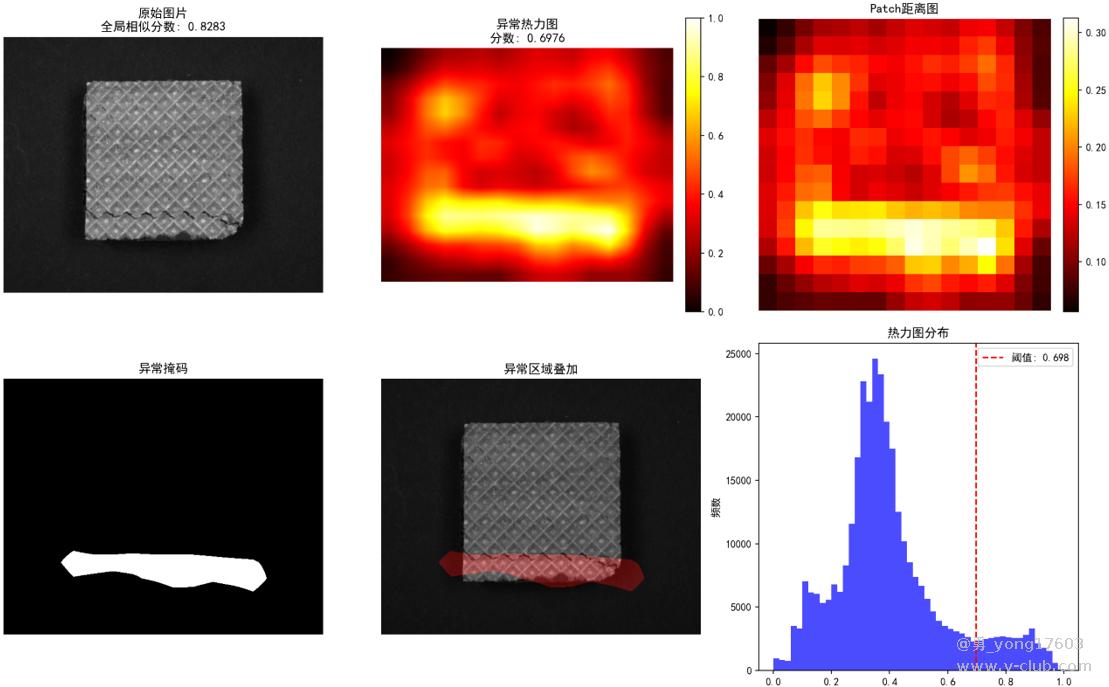
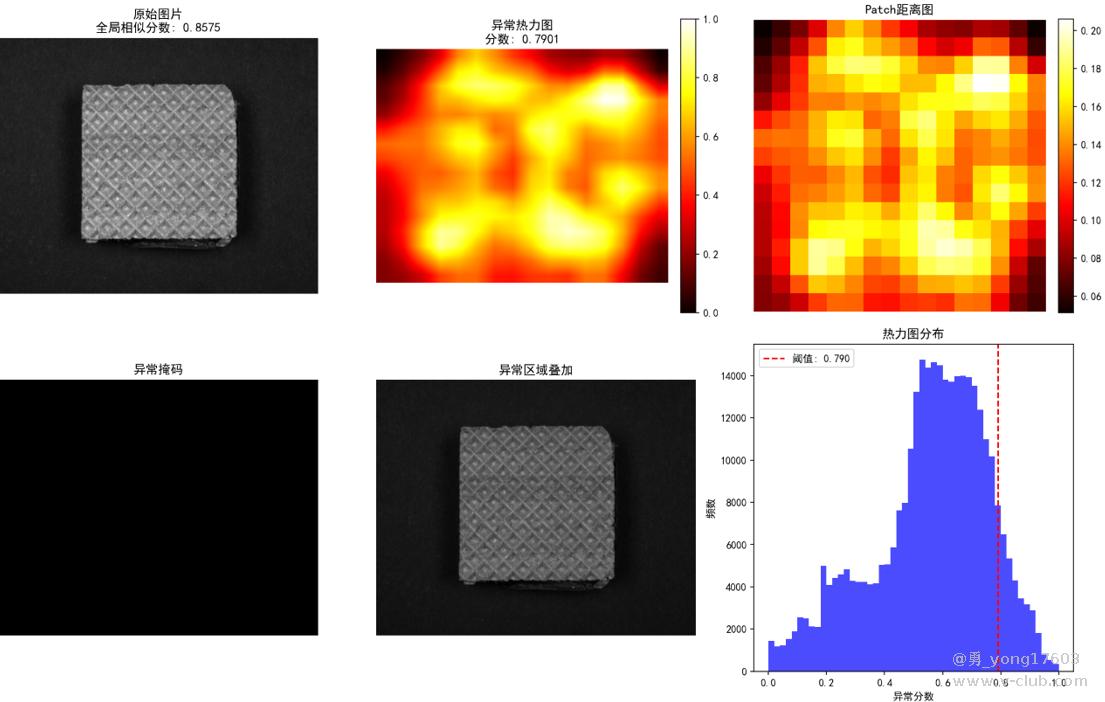
用的是一样的模型,一样的代码。检测不同类别的缺陷。检出率100%。我看到结果的时候也吓了一跳。这些都是之前很难检测的。因为缺陷不好量化描述。比yolo,cnn对比优势太明显了。不用标注,不用训练。只要极少正样本。本贴用的是halcon案例图片。
好消息,有了好方法。开发更轻松了。
坏消息,以后检测算法开发,不需要你了。
欢迎大家投稿给我,我帮你测试检测效果。效果很好。个人感觉比vm效果好。而且不用训练,不用训练,不用训练,cpu就能跑。因为模型是科技公司海量数据训练好的。我只是去掉了它的最后的输出头。保留其模型强大的特征提取功能。然后滑窗对图片做相识度比较。再映射回原图。确定缺陷以及缺陷位置。比你自己训练效果好很多。
版权声明:本文为V社区用户原创内容,转载时必须标注文章的来源(V社区),文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件至:v-club@hikrobotics.com 进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容。

评论请先登录 登录
全部评论 8


- 1

相关阅读
 基于基础应用扩展的偏心抓取算法2026-07-07
基于基础应用扩展的偏心抓取算法2026-07-07 话术-用AI协助编写VM3D脚本模块的代码2026-06-29
话术-用AI协助编写VM3D脚本模块的代码2026-06-29 博图半导体SOP封装视觉检测方案2026-06-25
博图半导体SOP封装视觉检测方案2026-06-25
 浙公网安备 33010802013223号
浙公网安备 33010802013223号