- 0
- 0
- 分享
- 2026-06-08 18:48
数据上的困难
比赛给的数据只有十几张,既不够训练深度学习模型,也不够调试测量流程。我们决定自己扩展数据集。按照真实缺陷的类型,人工制作了多种缺陷样本,同时控制了光照、瓶子在画面中的位置、瓶内水位这几个变量。最终形成了几千张可用于训练和测试的图像。
方案的整体结构
我们把流程分成两路并行。一路做尺寸测量,通过快速匹配定位瓶子,再经过位置修正使瓶子居中,然后用直线查找和线线测量得到瓶盖宽度和瓶身高度。另一路做标签缺陷检测,先匹配标签区域,修正位置后裁剪出标签,再用深度学习图像分割模型做像素级识别,最后通过Blob分析输出缺陷位置和类别。两路互不干扰,可以独立调整。
模型的选择
对比过无监督分割、分类和图像分割。矿泉水瓶上的划痕、缺笔画这类缺陷比较细小,分类模型只能告诉有无问题,无法定位。无监督分割在某些简单场景可用,但我们的缺陷类型多且组合复杂,不够稳定。最后选择有监督的图像分割,虽然训练成本更高,但检出效果最符合需求。
界面和人机交互
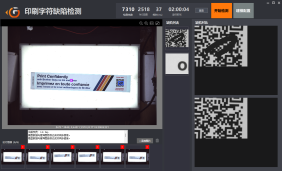
界面用VM自带的运行界面模块搭建。主要包含三部分:渲染图展示区(用Tab页分别显示瓶身高度、瓶盖宽度和标签缺陷)、检测结果统计(当前图像信息、缺陷列表、已检测数量)、历史数据和饼图(OK/NG占比、缺陷类型占比)。另外加了清空统计、历史最长最短耗时这些功能,调试时比较有用。
一点体会
这个题目看起来是做一个检测方案,但实际做下来发现,数据、流程设计、模型选择、界面落地的每一块都要花不少精力。双路并行的结构让我们后期调整比较方便。深度分割模型对微小缺陷的效果明显好于分类。界面方面,功能不是越多越好,但常用的统计和记录确实提升了方案的可演示性。
比赛结束后回头看,这次项目让我们完整走了一遍从数据构造到系统集成的过程。也验证了传统视觉算子和深度学习可以在一个方案里配合使用。如果有机会在真实产线上继续测试,应该能发现更多可以优化的细节。


 【形状匹配算法系列】从NCC到轮廓匹配:工业视觉的"定位之争",到底争的是什么?2026-05-19
【形状匹配算法系列】从NCC到轮廓匹配:工业视觉的"定位之争",到底争的是什么?2026-05-19 使用VM算法识别屏幕2026-06-05
使用VM算法识别屏幕2026-06-05 移动机器人工程师培训与认证安排-26年6月2026-05-18
移动机器人工程师培训与认证安排-26年6月2026-05-18- 移动机器人技术分享-26年5月2026-05-15
 【第四届启智杯大赛决赛】+开发赛道+迹你实在是太美+参赛作品分享2026-06-01
【第四届启智杯大赛决赛】+开发赛道+迹你实在是太美+参赛作品分享2026-06-01
 浙公网安备 33010802013223号
浙公网安备 33010802013223号