


- 什么是深度学习?
- 深度学习的前沿研究与应用
- 深度学习和传统算法在缺陷检测应用中的特点
- 深度学习训练工具VisionTrain1.4.1功能更新说明
- 模型优化方法---通用基础篇
- 模型优化方法---VM算法平台预测篇
- 模型优化方法---VisionTrain训练篇
- 模型优化方法---预测耗时篇
- 深度学习小工具之快速图像分割
- 深度学习小工具之标签转化工具
- 深度学习小工具之图像名称、标签文件内容修改工具
- 训练误差与泛化误差的关系
- 训练过程中对于误差值的理解
- 基本图像增强算法对深度学习模型结果的影响
- 使用VM深度学习功能实现模型训练与图像检索功能
- 智能相机-深度学习OCR训练及优化指南
- 一种提升OCR模型识别率的优化方法
- 根据实际需求找到最优方案-OCR识别篇
- 多分类分割任务下实现指定类别的阈值调整
- 多分类分割任务下的标注问题及解决思路
- 图像分割标注训练经验分享
- 基于VM界面层的多类别缺陷统计方案
- VM深度学习OCR项目经验分享
- 【VM集成开源AI】深度学习算子模块封装
- 深度学习推理耗时波动现象的解决方法
- 【共享学习】关于深度学习显卡推理那些事儿
- VM7100深度学习检测温度传感器焊点,裸针,锡珠,超盘,
- 深度学习缺陷检测项目经验分享
- 深度学习基础介绍
- 深度学习VS注册学习
智能相机-深度学习OCR训练及优化指南
- 0
- 0
- 分享
- 2023-04-03 14:22
在智能相机的使用过程中,如何使深度学习OCR应用效果更好且更快的落地,是不少深度学习项目推动过程比较关注且重要的节点,文章通过数据收集打标、训练、优化三个方面,对应用进行说明,为深度学习OCR提供一些经验。
一、训练集收集打标注意事项
采图任务建议使用相机存图功能或FTP存图,提前架设好相机位置调节曝光、焦点等参数至最佳,取与实际运行时同工作距离下同场景、同分辨率和同参数条件下的图片打标作为训练集,采图要求有:
(1)图片中字符需存在位置、角度、内容等变化,保证样本的丰富性,作为深度学习模型训练的基础。
(2)“DL字符定位”对字符、图像的要求:字符高度分辨率≥12/528×图像宽高中较大者分辨率,达到20/528×图像宽高中较大者分辨率以上效果最佳。若不满足要求,建议调整相机视野或工作距离

(3)采图数量一般在几十张至上百张,可根据OCR场景复杂度适当增加数量
1.2 数据打标
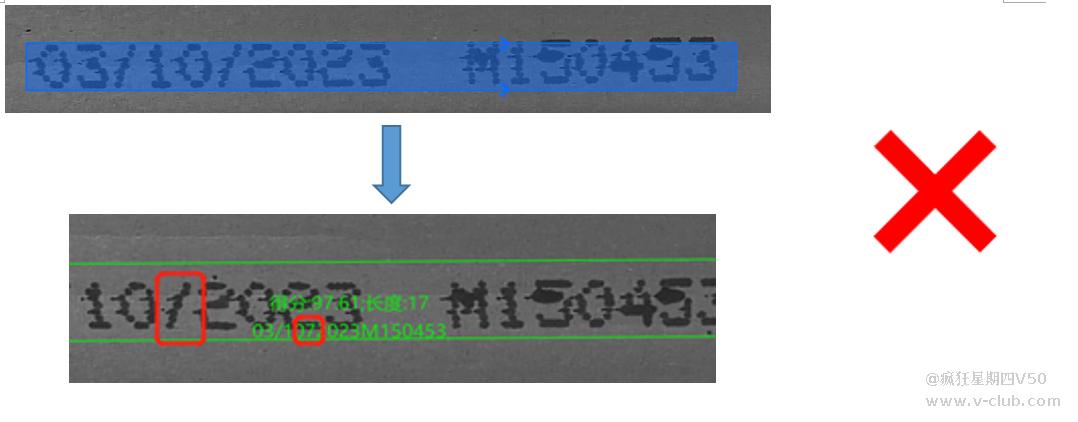
字符数据打标作为模型训练的基础,很大程度上决定了实际运行时的检测效果,在打标时应该遵守“矩形框的方向和字符本身的方向保持一致,大小为上下边沿贴近字符边沿,左右预留1/2字符宽度“的规则,
注:矩形框上下应贴合但不黏连字符,否则可能会造成误识别

二、模型训练常见问题指南
2.1 训练流程及注意事项
以下以当前使用率较高的AI训练平台为例进行说明
AI训练平台蓝网V2.2版本:http://10.43.108.20/
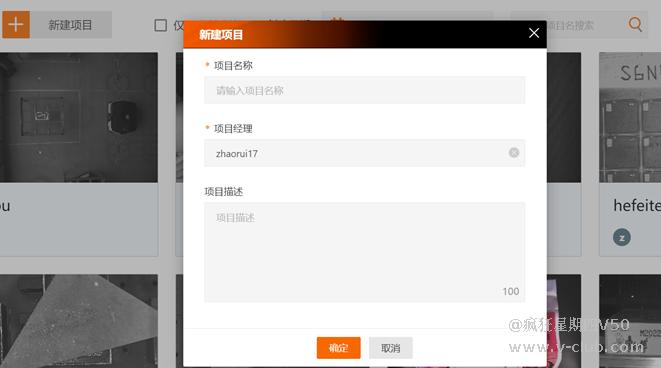
(1)新建项目-输入项目名称创建
(2)新建数据集
l 训练集:用于训练模型的数据集,上传数据集进行打标训练
l 验证集:用于验证模型能力的数据集,无需打标
标注方式默认文本行定位/识别(定位与识别数据上传后互通)

(3)导入训练集时根据实际情况可选择有/无标注信息
l 无标注信息文件格式:可上传图片(.jpg、.jpeg、.png、.bmp)或压缩包(.zip)
上传后在平台上进行打标
l 有标注信息文件格式:可上传压缩包(.zip)
注:带标注的压缩包算法类型需要与当前数据集算法类型一致
(4)模型中心-模型训练-新建模型,选择训练定位或识别模型
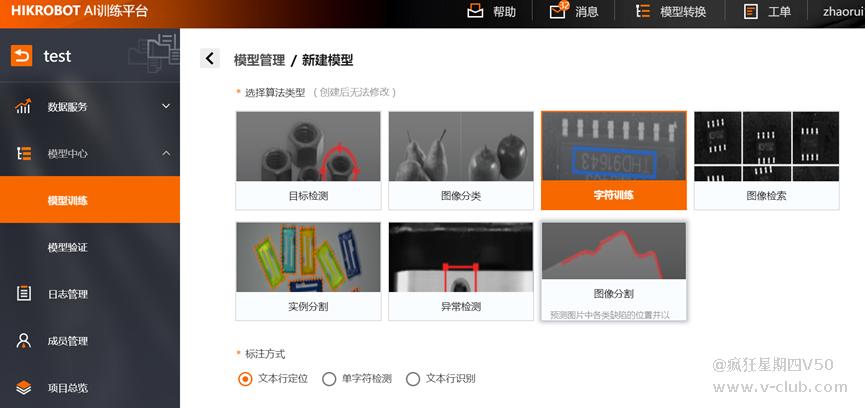
l 选择数据集:添加步骤(2)上传的数据集
l 目标平台:SC智能相机
l 相机系列:根据实际情况选择
l 迭代轮次:根据训练集图片数量决定,一般30张设置800轮,100张设置600轮,200张设置400轮,500张设置250轮,1000张设置150轮,5000张设置100轮,10000张设置80轮。
若出现漏识别、多识别的情况,可以尝试增加训练样本、增大最大迭代次数优化模型效果。
迭代轮次可根据实际情况适当调整,但不宜过大或过小,否则可能造成模型过拟合或欠拟合。
l 基础学习率:指模型参数更新幅度的大小,一般默认1无需改动。
l 是否训练带朝向:根据实际情况选择,未开启时默认定位-90°到90°的字符,超出时识别方向与字符正确方向相反会导致识别错误;开启时可识别到-180°到180°的字符。
(5)训练曲线与误差

注:训练误差指模型在训练集中的误差,与实际模型运行效果无关,训练误差可通过提高迭代轮次等方法减小,但不代表实际运行验证时模型误差更小。
n 训练异常时可提供任务ID给总部技术支持人员进行问题排查


注: AI 训练平台不支持SC3000 V1.0版本固件字符识别模型的训练及转换
三、模型优化方向指南
(1)【现场问题】:客户因保密或成本等原因可提供的数据图片有限,提供的字符种类涵盖不全,与实际生产运行时有一定差距
【解决方案】:①以目前可以获取到的字符为基础进行数据收集, 采集的图片需要涵盖字符位置、角度、内容变化
②需要客户提供字符字体的.ttf文件,如客户无法提供,最低限度需要和客户确认字体样式
总部根据提供的信息进行文本生成补全无法提供的字符种类。
(2)【现场问题】:定位出现无框、短框等现象
【解决方案】:①更新至最新算法库
②无框:检查排除打标问题、降低定位模型最小得分(默认50.一般不低于20)
③短框:可能因字符分段造成热力图断开,可考虑优化打标矩形框长度或绘制多个ROI定位
如常规方法无法满足,可联系总部进行数据增强等方式。
(3)【现场问题】:识别出现误识别、漏识别等现象
【解决方案】:①更新至最新算法库
②检查排除打标问题
③训练集应涵盖误识别的所有字符种类,如某一字符样本过多可能造成对形态相近字符的误识别
④调整文本框回复缩放值(默认180.一般不大于250)
⑤针对文本过长导致漏识别的现象,建议提供数据联系总部优化
如常规方法无法满足,可联系总部售前
(4)【现场问题】:字符与背景灰度差较小,背景干扰严重造成识别率较低
【解决方案】:①调整曝光或增益,设置过曝来区分字符与背景
②换用其他颜色光源
③适当增加训练集样本数量
如常规方法无法满足,可联系总部进行文本合成等方式
- 其他模型问题请联系总部技术支持人员进行分析排查
四、常见问题Q&A
(1)Q:需要联系总部人员进行优化时,图片以什么形式提供呢
A:训练集图片(BMP格式),JPG图片可能存在传输过程中损坏等因素,导致本地测试与现场出现误差
(1) Q:AI训练平台账号如何获取?
A:请联系对应区域销售,交由联系总部相关人员
(2) Q:面对个数据保密的客户,AI训练平台安全性如何
A:平台同时支持私有化部署和公有云部署,数据上传安全可靠,绝无泄露风险
(3) Q:现场场景和产品种类冗多,客户不愿一一采图,有无好的解决办法
A:请收集目前可以提供的现场产品图片及商机信息联系总部售前进行评估
(4) Q:平台训练生成的模型无法导入相机
A:①排查定位与识别模型是否混淆
②不同型号相机模型不互通,排查是否导入正确型号相机
③如模型名称过长,需要修改模型名称(.bin格式后缀不可修改)
如仍无法导入,请联系区域技术人员
- 有其他任何问题可联系区域技术支持人员进行排查
版权声明:本文为V社区用户原创内容,转载时必须标注文章的来源(V社区),文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件至:v-club@hikrobotics.com 进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容。
评论请先登录 登录
全部评论 0

所属专题
相关阅读
 【形状匹配算法系列】从NCC到轮廓匹配:工业视觉的"定位之争",到底争的是什么?2026-05-19
【形状匹配算法系列】从NCC到轮廓匹配:工业视觉的"定位之争",到底争的是什么?2026-05-19 【技术分享】VM运行界面之清空图像2026-06-10
【技术分享】VM运行界面之清空图像2026-06-10 使用VM算法识别屏幕2026-06-05
使用VM算法识别屏幕2026-06-05 认证刷题与模拟考试系统2026-06-12
认证刷题与模拟考试系统2026-06-12- 移动机器人工程师培训与认证安排-26年6月2026-05-18
 浙公网安备 33010802013223号
浙公网安备 33010802013223号