

- 什么是深度学习?
- 深度学习的前沿研究与应用
- 深度学习和传统算法在缺陷检测应用中的特点
- 深度学习训练工具VisionTrain1.4.1功能更新说明
- 模型优化方法---通用基础篇
- 模型优化方法---VM算法平台预测篇
- 模型优化方法---VisionTrain训练篇
- 模型优化方法---预测耗时篇
- 深度学习小工具之快速图像分割
- 深度学习小工具之标签转化工具
- 深度学习小工具之图像名称、标签文件内容修改工具
- 训练误差与泛化误差的关系
- 训练过程中对于误差值的理解
- 基本图像增强算法对深度学习模型结果的影响
- 使用VM深度学习功能实现模型训练与图像检索功能
- 智能相机-深度学习OCR训练及优化指南
- 一种提升OCR模型识别率的优化方法
- 根据实际需求找到最优方案-OCR识别篇
- 多分类分割任务下实现指定类别的阈值调整
- 多分类分割任务下的标注问题及解决思路
- 图像分割标注训练经验分享
- 基于VM界面层的多类别缺陷统计方案
- VM深度学习OCR项目经验分享
- 【VM集成开源AI】深度学习算子模块封装
- 深度学习推理耗时波动现象的解决方法
- 【共享学习】关于深度学习显卡推理那些事儿
- VM7100深度学习检测温度传感器焊点,裸针,锡珠,超盘,
- 深度学习缺陷检测项目经验分享
- 深度学习基础介绍
- 深度学习VS注册学习
【共享学习】关于深度学习显卡推理那些事儿
- 0
- 1
- 分享
- 2023-09-07 11:18
深度学习是机器视觉领域越来越火的方向,各家卯足干劲奔赴AI,以至于逢年过节,机器视觉从业者见面寒暄第一句多半都是:“今天你打标了吗?”针对机器视觉深度学习显卡推理过程及常见问题点,结合个人多年经验做出解答。
要想获得解决方案,首先需要了解原理。为向大家更直观地描述深度学习显卡推理的完整过程,画了一张精简的图如下:

结合个人经验,总结如下:
- 深度学习推理算法(GPU)并非全部在GPU上执行,图像拷贝、Resize等操作均是由CPU处理。由于主板内存和显卡内存物理上独立且无法转换(无法使用虚拟内存技术将硬盘内存转换为显存),因此图像数据需要先从内存上传到显存,经过CUDA并行推理后,再从显存下载到内存(才能被后续模块处理或显示)。
- 在算法平台中看到的输入图像和输出图像(概率缺陷图等)都是主板内存中的图像。
- 当显卡利用率不高时,耗时波动瓶颈在CPU对图像的预处理操作,以及图像上传、下载。因此,可以通过提升CPU来减少耗时波动。
- 当显卡利用率不高时,耗时瓶颈在显卡的运行频率。因此,可以通过超频工具锁频处理来减少耗时。超频工具可以网上下载或联系区域技术人员获取。
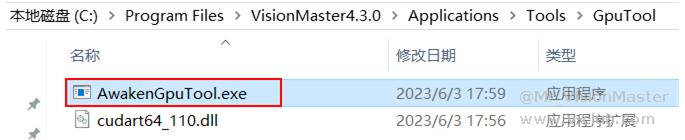
- 显卡属于硬件设备,因此也有节能设置。显卡驱动每隔一段时间会检测GPU是否被调用,当检测到GPU一段时间内都没有被调用,GPU就会进入休眠状态,此时若有进程调用GPU,则显卡会从休眠状态进入运行状态,唤醒过程存在一定延时。因此,当设备待机一段时间再次运行时,深度学习算法耗时会突然变长,就是由于显卡休眠导致的。因此,可以通过设置显卡高性能模式,以及调用AwakenGpuTool.exe(针对算子SDK开发客户,VM平台会自动调用该工具)来保证显卡始终被唤醒。
AwakenGpuTool.exe工具路径如下:
版权声明:本文为V社区用户原创内容,转载时必须标注文章的来源(V社区),文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件至:v-club@hikrobotics.com 进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容。
上一篇
评论请先登录 登录
全部评论 1

- 1

所属专题
相关阅读
 【形状匹配算法系列】从NCC到轮廓匹配:工业视觉的"定位之争",到底争的是什么?2026-05-19
【形状匹配算法系列】从NCC到轮廓匹配:工业视觉的"定位之争",到底争的是什么?2026-05-19 【技术分享】VM运行界面之清空图像2026-06-10
【技术分享】VM运行界面之清空图像2026-06-10 使用VM算法识别屏幕2026-06-05
使用VM算法识别屏幕2026-06-05 认证刷题与模拟考试系统2026-06-12
认证刷题与模拟考试系统2026-06-12- 移动机器人工程师培训与认证安排-26年6月2026-05-18
 浙公网安备 33010802013223号
浙公网安备 33010802013223号