


- 探寻机器视觉新星|第二届“启智杯”机器视觉设计大赛获奖名单公布
- 第二届启智杯-666队
- 第二届启智杯——光伏电池片质检方案设计
- 第二届启智杯应用类-光伏电池片质检视觉方案设计
- 第二届启智杯—光伏电池片质检视觉方案设计-我恨月亮队
- 第二届启智杯-光伏电池片质检视觉方案设计
- 第二届启智杯—光伏电池片质检视觉方案设计
- 第二届启智杯——锂电外壳表面缺陷检测的3D视觉方案
- 第二届启智杯--能实现标准件检测的双目视觉系统设计
- 第二届启智杯--能实现标准件检测的双目视觉系统设计
- 第2届“启智杯”设计大赛——一种锂电外壳外观检测3D视觉方案
- 第二届启智杯-锂电外壳外观检测3D视觉方案设计
- 第二届启智杯-锂电外壳外观检测3D视觉方案设计
- 第二届启智杯—锂电外壳外观检测3D视觉方案设计
- 第二届启智杯-无监督异常检测算法
- 第二届“启智杯”设计大赛-能实现标准件检测的双目系统设计
- 第二届启智杯-创意赛道-众智队-能实现标准件检测的双目视觉系统设计
- 第二届启智杯--能实现标准件检测的双目视觉系统设计
- 第二届“启智杯”设计大赛-能实现标准件检测的双目系统设计
- 第二届启智杯--能实现标准件检测的双目视觉系统设计
- 第二届“启智杯”可视化流程编辑器-基于坐标变换实现整体框架
- 第二届启智杯-一个可视化流程编辑器
- 第二届启智杯-一种可视化流程编辑器
- 第二届启智杯——节点数据订阅设计
- 第二届启智杯-无监督异常检测算法
- 《第二届启智杯-试一试队-算法赛道-无监督异常检测算法》
- 第二届启智杯-小样本计数算法
- 第二届启智杯-小样本计数-新疆核桃小队
- 第二届启智杯-小样本计数-海康正式员工队
- 第二届“启智杯”算法赛道-小样本计数算法设计报告-态度诚恳队
第二届启智杯-无监督异常检测算法
- 0
- 0
- 分享
- 2024-04-16 09:26
“启智杯”算法赛道命题-无监督异常检测算法。在该命题中,要求让学习到的模型能够区分正常样本和异常样本,在训练时只能获取正常样本,测试时能分辨出缺陷样本,并提供缺陷的区域信息,输出缺陷分割图(一张二值图)。本文提出一种无监督异常检测算法,希望能与大家讨论交流,以改善此算法。语言:python。框架:pytorch。
一.任务难点分析
- PCB 样本被放置在银白色带有黑色边框的拍摄平台上,该平台略有反光并且存在大量划痕,
这会对模型的处理存在大量的干扰信息。
- PCB 样品仅占图片中很小的面积这不仅会让背景干扰模型的判断,并且无用的像素会大量浪
费计算资源和存储空间造成分割精度下降和延长运行耗时。
- PCB 以非固定的角度放置在拍摄平台的随机位置,这不利于我们定位 PCB 的位置,难以排除背景干扰。
- 每个 PCB 类别仅有 50 张训练用的正常样本,训练样本过少,这可能会造成模型对这些样本
过拟合,泛化性能不够等问题。
- PCB 板是一个极为复杂的样本,与常见的工业无监督异常分割数据集相比即使是正常 PCB
样本其纹理也极为复杂这给分割任务造成了极大的困难。
- 正常 PCB 样本中依然存在轻微的瑕疵,但是在异常样本中这些轻微瑕疵被标注出来,这是由于瑕疵的多样性和无法标注界定所造成的问题,然而由于正常样本中这些轻微瑕疵被认为 是正常部分,所以异常样本中的轻微瑕疵也将很难被模型检测出来造成漏检的问题。
二.PCB裁切
为了消除干扰便于后续模型处理,使用模板匹配算法匹配PCB实体并裁切。
模板匹配算法使用opencv的cv2.matchTemplate实现。并使用下采样和粗匹配降低耗时。具体如下:
- 手动制作PCB模板
- 将PCB样本图片与PCB模板做适当倍率的下采样。
- 重复旋转下采样后的PCB样本图片每次5°,并调用cv2.matchTemplate算子计算匹配度,并记录最佳匹配的角度信息。
- 使用未下采样的PCB样本图片与PCB模板,根据记录的最佳角度在其±2°范围内按1°每次旋转PCB样本图片并使用匹配算子匹配,记录最佳匹配角度与位置信息。
- 根据记录的角度与位置信息裁切PCB样本图片中的PCB实体(效果如下图所示)。

三.模型算法思路
沿用EfficientAD的大体思路,提供三个模型共同实现异常检测。
教师模型、学生模型与自编码器模型。
教师模型为加载预训练权重的WideResNet-101。学生模型为轻量化的PDN模型。自编码器模型使用EfficientAD构建的标准卷积自编码器。
我们放弃使用PDN模型蒸馏WideResNet-101的方式,而直接使用WideResNet-101,原因如下:
- ImageNet 数据集需要大量的内存资源和计算资源,使用 WideResNet-101 蒸馏得到教师模
型需要消耗较长的时间。
- 使用我们现有的硬件资源蒸馏后得到的教师模型似乎并没有得到很好的效果。
- WideResNet-101 的预训练权重经过反复验证,直接使用比较安全,虽然推理时间会有所增加。
我们对EfficientAD中模型的结构做了简单的调整以适应后续的训练(代码如下)。
import torch.nn as nn
import torch
import torch.nn.functional as F
from thop import profile
try:
from torch.hub import load_state_dict_from_url
except ImportError:
from torch.utils.model_zoo import load_url as load_state_dict_from_url
from torchvision.models.resnet import ResNet, Bottleneck
import torchvision
def weights_init(m):
classname = m.__class__.__name__
if classname.find('Conv2d') != -1:
m.weight.data.normal_(0.0, 0.02)
elif classname.find('BatchNorm') != -1:
m.weight.data.normal_(1.0, 0.02)
m.bias.data.fill_(0)
def imagenet_norm_batch(x):
mean = torch.tensor([0.485, 0.456, 0.406])[None, :, None, None].to('cuda')
std = torch.tensor([0.229, 0.224, 0.225])[None, :, None, None].to('cuda')
x_norm = (x - mean) / (std + 1e-11)
return x_norm
class WideResNet(ResNet):
def __init__(self, block, layers, num_classes=1000, zero_init_residual=False,
groups=1, width_per_group=64, replace_stride_with_dilation=None,
norm_layer=None, target_dim=384):
super(WideResNet, self).__init__(block, layers, num_classes, zero_init_residual,
groups, width_per_group, replace_stride_with_dilation,
norm_layer)
self.target_dim = target_dim
def _forward_impl(self, x):
# x = imagenet_norm_batch(
# x) # Comments on Algorithm 3: We use the image normalization of the pretrained models of torchvision [44].
# See note [TorchScript super()]
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x0 = self.layer1(x)
x1 = self.layer2(x0)
x2 = self.layer3(x1)
# pdb.set_trace()
ret = self._proj(x1, x2)
# x3 = self.layer4(x)
# x = self.avgpool(x)
# x = torch.flatten(x, 1)
# x = self.fc(x)
ret = F.interpolate(ret, scale_factor=2, mode="bilinear")
return ret
def _proj(self, x1, x2):
# [2, 512, 64, 64]->[2, 512, 64, 64],[2, 1024, 32, 32]->[2, 1024, 64, 64]
# cat [2, 512, 64, 64],[2, 1024, 64, 64]->[2, 1536, 64, 64]
# pool [2, 1536, 64, 64]->[2, 384, 32, 32]
b, c, h, w = x1.shape
x2 = F.interpolate(x2, size=(h, w), mode="bilinear", align_corners=False)
features = torch.cat([x1, x2], dim=1)
b, c, h, w = features.shape
features = features.reshape(b, c, h * w)
features = features.transpose(1, 2)
target_features = F.adaptive_avg_pool1d(features, self.target_dim)
# pdb.set_trace()
target_features = target_features.transpose(1, 2)
target_features = target_features.reshape(b, self.target_dim, h, w)
return target_features
def _resnet(url, block, layers, pretrained, progress, **kwargs):
model = WideResNet(block, layers, **kwargs)
if pretrained:
state_dict = load_state_dict_from_url(url, progress=progress)
model.load_state_dict(state_dict)
return model
def wide_resnet101_2(arch, pretrained=False, progress=True, **kwargs):
r"""Wide ResNet-101-2 model from
`"Wide Residual Networks" <https://arxiv.org/pdf/1605.07146.pdf>`_
The model is the same as ResNet except for the bottleneck number of channels
which is twice larger in every block. The number of channels in outer 1x1
convolutions is the same, e.g. last block in ResNet-50 has 2048-512-2048
channels, and in Wide ResNet-50-2 has 2048-1024-2048.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
progress (bool): If True, displays a progress bar of the download to stderr
"""
kwargs['width_per_group'] = 64 * 2
url = torchvision.models.get_weight(arch).url
return _resnet(url, Bottleneck, [3, 4, 23, 3],
pretrained, progress, **kwargs)
class PDN_S(nn.Module):
def __init__(self, last_kernel_size=384, with_bn=False) -> None:
super().__init__()
# Layer Name Stride Kernel Size Number of Kernels Padding Activation
# Conv-1 1×1 4×4 128 3 ReLU
# AvgPool-1 2×2 2×2 128 1 -
# Conv-2 1×1 4×4 256 3 ReLU
# AvgPool-2 2×2 2×2 256 1 -
# Conv-3 1×1 3×3 256 1 ReLU
# Conv-4 1×1 4×4 384 0 -
self.with_bn = with_bn
self.conv1 = nn.Conv2d(3, 128, kernel_size=4, stride=1, padding=3)
self.conv2 = nn.Conv2d(128, 256, kernel_size=4, stride=1, padding=3)
self.conv3 = nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1)
self.conv4 = nn.Conv2d(256, last_kernel_size, kernel_size=4, stride=1, padding=0)
self.avgpool1 = nn.AvgPool2d(kernel_size=2, stride=2, padding=1)
self.avgpool2 = nn.AvgPool2d(kernel_size=2, stride=2, padding=1)
if self.with_bn:
self.bn1 = nn.BatchNorm2d(128)
self.bn2 = nn.BatchNorm2d(256)
self.bn3 = nn.BatchNorm2d(256)
self.bn4 = nn.BatchNorm2d(last_kernel_size)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x) if self.with_bn else x
x = F.relu(x)
x = self.avgpool1(x)
x = self.conv2(x)
x = self.bn2(x) if self.with_bn else x
x = F.relu(x)
x = self.avgpool2(x)
x = self.conv3(x)
x = self.bn3(x) if self.with_bn else x
x = F.relu(x)
x = self.conv4(x)
x = self.bn4(x) if self.with_bn else x
return x
class PDN_M(nn.Module):
def __init__(self, last_kernel_size=384, with_bn=False) -> None:
super().__init__()
# Layer Name Stride Kernel Size Number of Kernels Padding Activation
# Conv-1 1×1 4×4 256 3 ReLU
# AvgPool-1 2×2 2×2 256 1 -
# Conv-2 1×1 4×4 512 3 ReLU
# AvgPool-2 2×2 2×2 512 1 -
# Conv-3 1×1 1×1 512 0 ReLU
# Conv-4 1×1 3×3 512 1 ReLU
# Conv-5 1×1 4×4 384 0 ReLU
# Conv-6 1×1 1×1 384 0 -
self.conv1 = nn.Conv2d(3, 256, kernel_size=4, stride=1, padding=3)
self.conv2 = nn.Conv2d(256, 512, kernel_size=4, stride=1, padding=3)
self.conv3 = nn.Conv2d(512, 512, kernel_size=1, stride=1, padding=0)
self.conv4 = nn.Conv2d(512, 512, kernel_size=3, stride=1, padding=1)
self.conv5 = nn.Conv2d(512, last_kernel_size, kernel_size=4, stride=1, padding=0)
self.conv6 = nn.Conv2d(last_kernel_size, last_kernel_size, kernel_size=1, stride=1, padding=0)
self.avgpool1 = nn.AvgPool2d(kernel_size=2, stride=2, padding=1)
self.avgpool2 = nn.AvgPool2d(kernel_size=2, stride=2, padding=1)
if self.with_bn:
self.bn1 = nn.BatchNorm2d(256)
self.bn2 = nn.BatchNorm2d(512)
self.bn3 = nn.BatchNorm2d(512)
self.bn4 = nn.BatchNorm2d(512)
self.bn5 = nn.BatchNorm2d(last_kernel_size)
self.bn6 = nn.BatchNorm2d(last_kernel_size)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x) if self.with_bn else x
x = F.relu(x)
x = self.avgpool1(x)
x = self.conv2(x)
x = self.bn2(x) if self.with_bn else x
x = F.relu(x)
x = self.avgpool2(x)
x = self.conv3(x)
x = self.bn3(x) if self.with_bn else x
x = F.relu(x)
x = self.conv4(x)
x = self.bn4(x) if self.with_bn else x
x = F.relu(x)
x = self.conv5(x)
x = self.bn5(x) if self.with_bn else x
x = F.relu(x)
x = self.conv6(x)
x = self.bn6(x) if self.with_bn else x
return x
class EncConv(nn.Module):
def __init__(self) -> None:
super().__init__()
# Layer Name Stride Kernel Size Number of Kernels Padding Activation
# EncConv-1 2×2 4×4 32 1 ReLU
# EncConv-2 2×2 4×4 32 1 ReLU
# EncConv-3 2×2 4×4 64 1 ReLU
# EncConv-4 2×2 4×4 64 1 ReLU
# EncConv-5 2×2 4×4 64 1 ReLU
# EncConv-6 1×1 8×8 64 0 -
self.enconv1 = nn.Conv2d(3, 32, kernel_size=4, stride=2, padding=1)
self.enconv2 = nn.Conv2d(32, 32, kernel_size=4, stride=2, padding=1)
self.enconv3 = nn.Conv2d(32, 64, kernel_size=4, stride=2, padding=1)
self.enconv4 = nn.Conv2d(64, 64, kernel_size=4, stride=2, padding=1)
self.enconv5 = nn.Conv2d(64, 64, kernel_size=4, stride=2, padding=1)
self.enconv6 = nn.Conv2d(64, 64, kernel_size=3, stride=1, padding=1)
# self.apply(weights_init)
def forward(self, x):
# pdb.set_trace()
x = F.relu(self.enconv1(x))
x = F.relu(self.enconv2(x))
x = F.relu(self.enconv3(x))
x = F.relu(self.enconv4(x))
x = F.relu(self.enconv5(x))
x = self.enconv6(x)
return x
class DecBlock(nn.Module):
def __init__(self, scale_factor, stride, kernel_size, num_kernels, padding, activation, dropout_rate, ):
super().__init__()
self.activation = activation
# self.scale_factor = scale_factor
self.upsample = nn.Upsample(scale_factor=scale_factor, mode='bilinear')
self.deconv = nn.Conv2d(num_kernels, num_kernels, kernel_size, stride, padding)
self.dropout = nn.Dropout2d(p=dropout_rate)
def forward(self, x):
x = self.upsample(x)
x = F.relu(self.deconv(x))
x = self.dropout(x)
return x
class DecConv(nn.Module):
def __init__(self, is_bn=False, *args, **kwargs) -> None:
super().__init__(*args, **kwargs)
# Bilinear-1 Resizes the 1×1 input features maps to 3×3
# DecConv-1 1×1 4×4 64 2 ReLU
# Dropout-1 Dropout rate = 0.2
# Bilinear-2 Resizes the 4×4 input features maps to 8×8
# DecConv-2 1×1 4×4 64 2 ReLU
# Dropout-2 Dropout rate = 0.2
# Bilinear-3 Resizes the 9×9 input features maps to 15×15
# DecConv-3 1×1 4×4 64 2 ReLU
# Dropout-3 Dropout rate = 0.2
# Bilinear-4 Resizes the 16×16 input features maps to 32×32
# DecConv-4 1×1 4×4 64 2 ReLU
# Dropout-4 Dropout rate = 0.2
# Bilinear-5 Resizes the 33×33 input features maps to 63×63
# DecConv-5 1×1 4×4 64 2 ReLU
# Dropout-5 Dropout rate = 0.2
# Bilinear-6 Resizes the 64×64 input features maps to 127×127
# DecConv-6 1×1 4×4 64 2 ReLU
# Dropout-6 Dropout rate = 0.2
# Bilinear-7 Resizes the 128×128 input features maps to 64×64
# DecConv-7 1×1 3×3 64 1 ReLU
# DecConv-8 1×1 3×3 384 1 -
self.is_bn = is_bn
self.deconv1 = nn.Conv2d(64, 64, kernel_size=5, stride=1, padding=2)
self.deconv2 = nn.Conv2d(64, 64, kernel_size=5, stride=1, padding=2)
self.deconv3 = nn.Conv2d(64, 64, kernel_size=5, stride=1, padding=2)
self.deconv4 = nn.Conv2d(64, 64, kernel_size=5, stride=1, padding=2)
self.deconv5 = nn.Conv2d(64, 64, kernel_size=5, stride=1, padding=2)
self.deconv6 = nn.Conv2d(64, 64, kernel_size=5, stride=1, padding=2)
self.deconv7 = nn.Conv2d(64, 64, kernel_size=3, stride=1, padding=1)
self.deconv8 = nn.Conv2d(64, 384, kernel_size=3, stride=1, padding=1)
if self.is_bn:
self.dropout1 = nn.BatchNorm2d(64)
self.dropout2 = nn.BatchNorm2d(64)
self.dropout3 = nn.BatchNorm2d(64)
self.dropout4 = nn.BatchNorm2d(64)
self.dropout5 = nn.BatchNorm2d(64)
self.dropout6 = nn.BatchNorm2d(64)
else:
self.dropout1 = nn.Dropout(p=0.2)
self.dropout2 = nn.Dropout(p=0.2)
self.dropout3 = nn.Dropout(p=0.2)
self.dropout4 = nn.Dropout(p=0.2)
self.dropout5 = nn.Dropout(p=0.2)
self.dropout6 = nn.Dropout(p=0.2)
# self.apply(weights_init)
def forward(self, x):
# x = self.bilinear1(x)
# x = F.interpolate(x, size=3, mode='bilinear')
x = F.relu(self.deconv1(x))
x = self.dropout1(x)
x = F.relu(self.deconv2(x))
x = self.dropout2(x)
x = F.interpolate(x, scale_factor=2, mode='bilinear')
x = F.relu(self.deconv3(x))
x = self.dropout3(x)
x = F.relu(self.deconv4(x))
x = self.dropout4(x)
x = F.interpolate(x, scale_factor=2, mode='bilinear')
x = F.relu(self.deconv5(x))
x = self.dropout5(x)
x = F.relu(self.deconv6(x))
x = self.dropout6(x)
x = F.interpolate(x, scale_factor=2, mode='bilinear')
x = F.relu(self.deconv7(x))
x = self.deconv8(x)
return x
class AutoEncoder(nn.Module):
def __init__(self, is_bn=False, *args, **kwargs) -> None:
super().__init__(*args, **kwargs)
self.encoder = EncConv()
self.decoder = DecConv(is_bn=is_bn)
self.encoder.apply(weights_init)
self.decoder.apply(weights_init)
def forward(self, x):
# x = imagenet_norm_batch(
# x) # Comments on Algorithm 3: We use the image normalization of the pretrained models of torchvision [44].
x = self.encoder(x)
x = self.decoder(x)
return x
class Teacher(nn.Module):
def __init__(self, size, with_bn=False, channel_size=384, *args, **kwargs) -> None:
super().__init__(*args, **kwargs)
if size == 'M':
self.pdn = PDN_M(last_kernel_size=channel_size, with_bn=with_bn)
elif size == 'S':
self.pdn = PDN_S(last_kernel_size=channel_size, with_bn=with_bn)
self.pdn.apply(weights_init)
def forward(self, x):
# x = imagenet_norm_batch(
# x) # Comments on Algorithm 3: We use the image normalization of the pretrained models of torchvision [44].
x = self.pdn(x)
return x
class Student(nn.Module):
def __init__(self, size, with_bn=False, channel_size=768, *args, **kwargs) -> None:
super().__init__(*args, **kwargs)
if size == 'M':
self.pdn = PDN_M(last_kernel_size=channel_size,
with_bn=with_bn) # The student network has the same architecture,but 768 kernels instead of 384 in the Conv-5 and Conv-6 layers.
elif size == 'S':
self.pdn = PDN_S(last_kernel_size=channel_size,
with_bn=with_bn) # The student network has the same architecture, but 768 kernels instead of 384 in the Conv-4 layer
self.pdn.apply(weights_init)
def forward(self, x):
# x = imagenet_norm_batch(
# x) # Comments on Algorithm 3: We use the image normalization of the pretrained models of torchvision [44].
pdn_out = self.pdn(x)
return pdn_out
if __name__ == "__main__":
device = "cuda"
input = torch.randn((1, 3, 224, 512), device=device)
Teacher = wide_resnet101_2("Wide_ResNet101_2_Weights.IMAGENET1K_V2", pretrained=True)
Teacher = Teacher.to(device)
Teacher.eval()
flops, params = profile(Teacher, (input,))
print("Teacher: flops: {:.4f} G".format(flops / 1000 ** 3), "params: {:.4f} M".format(params / 1000 ** 2))
student = Student("S", True).to(device)
out2 = student(input)
flops, params = profile(student, (input,))
print("Student: flops: {:.4f} G".format(flops / 1000 ** 3), "params: {:.4f} M".format(params / 1000 ** 2))
ae = AutoEncoder(True).to(device)
flops, params = profile(ae, (input,))
print("AutoEncoder: flops: {:.4f} G".format(flops / 1000 ** 3), "params: {:.4f} M".format(params / 1000 ** 2))
四、异常样本模拟
- 生成柏林噪声图并使用阈值算法生成异常掩码图。
- 使用掩码结合纹理图片或混乱的PCB图片模拟PCB中的纹理异常或逻辑异常部分。
- 将异常部分与正常部分叠加模拟异常PCB板(如图所示)。


五、训练与推理
EfficientAD从ImageNet数据集中随机抽取图片,主动将教师与学生模型在不同域的的特征距离拉远。然而在由于域的不同,我们将这一步更改为第四步生成的异常样本模拟图片。修改后训练流程如下图所示。
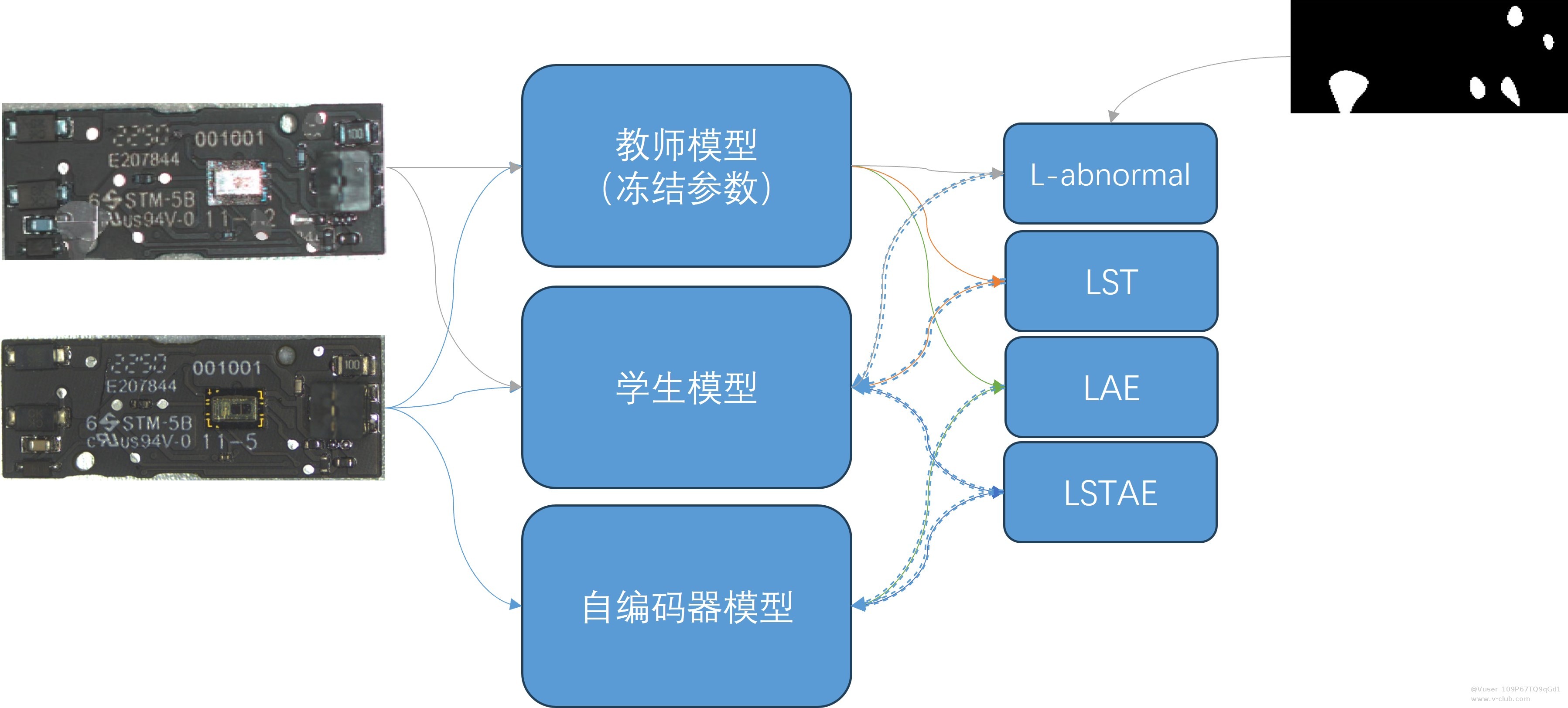
L-abnormal损失函数公式如下:

推理流程如下图所示:
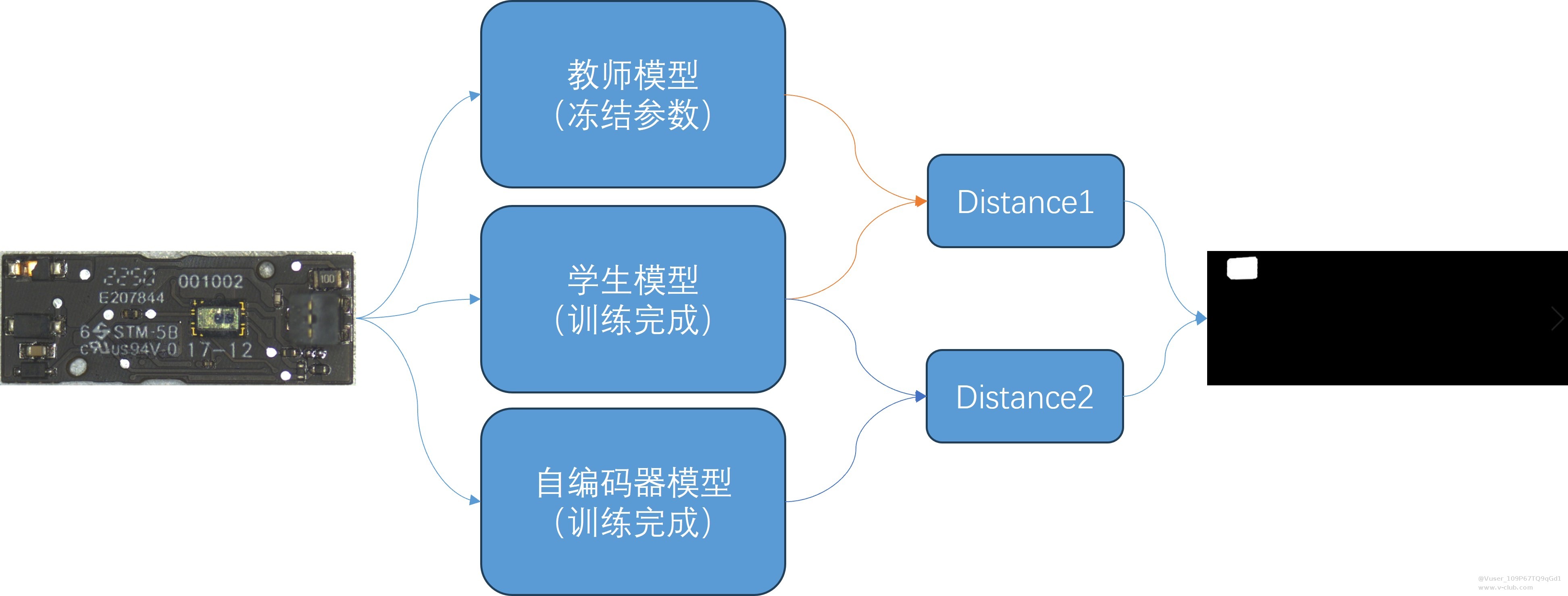
六、结果图
绿色部分为检测出的异常部分(真阳性),蓝色为检测出来但不是异常的部分(假阳性),红色为未检测出来的异常部分(假阴性)。

从结果中发现存在较多假阳性,后续有待改进。
初次写博客,可能有许多表述不清楚或者细节没讲到位的地方,欢迎大家批评指正。
附件:
版权声明:本文为V社区用户原创内容,转载时必须标注文章的来源(V社区),文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件至:v-club@hikrobotics.com 进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容。
上一篇
下一篇
评论请先登录 登录
全部评论 0

所属专题
相关阅读
 【形状匹配算法系列】从NCC到轮廓匹配:工业视觉的"定位之争",到底争的是什么?2026-05-19
【形状匹配算法系列】从NCC到轮廓匹配:工业视觉的"定位之争",到底争的是什么?2026-05-19 【技术分享】VM运行界面之清空图像2026-06-10
【技术分享】VM运行界面之清空图像2026-06-10 使用VM算法识别屏幕2026-06-05
使用VM算法识别屏幕2026-06-05 认证刷题与模拟考试系统2026-06-12
认证刷题与模拟考试系统2026-06-12- 移动机器人工程师培训与认证安排-26年6月2026-05-18
 浙公网安备 33010802013223号
浙公网安备 33010802013223号