



- 什么是深度学习?
- 深度学习的前沿研究与应用
- 深度学习和传统算法在缺陷检测应用中的特点
- 深度学习训练工具VisionTrain1.4.1功能更新说明
- 模型优化方法---通用基础篇
- 模型优化方法---VM算法平台预测篇
- 模型优化方法---VisionTrain训练篇
- 模型优化方法---预测耗时篇
- 深度学习小工具之快速图像分割
- 深度学习小工具之标签转化工具
- 深度学习小工具之图像名称、标签文件内容修改工具
- 训练误差与泛化误差的关系
- 训练过程中对于误差值的理解
- 基本图像增强算法对深度学习模型结果的影响
- 使用VM深度学习功能实现模型训练与图像检索功能
- 智能相机-深度学习OCR训练及优化指南
- 一种提升OCR模型识别率的优化方法
- 根据实际需求找到最优方案-OCR识别篇
- 多分类分割任务下实现指定类别的阈值调整
- 多分类分割任务下的标注问题及解决思路
- 图像分割标注训练经验分享
- 基于VM界面层的多类别缺陷统计方案
- VM深度学习OCR项目经验分享
- 【VM集成开源AI】深度学习算子模块封装
- 深度学习推理耗时波动现象的解决方法
- 【共享学习】关于深度学习显卡推理那些事儿
- VM7100深度学习检测温度传感器焊点,裸针,锡珠,超盘,
- 深度学习缺陷检测项目经验分享
- 深度学习基础介绍
- 深度学习VS注册学习
基于VM界面层的多类别缺陷统计方案
- 0
- 4
- 分享
- 2022-11-15 14:34
本文针对多分类任务下的缺陷统计需求,对比分析了两种VM方案
在实际缺陷检测项目中,为方便操作员直观了解缺陷占比,以评估生产质量,通常会在软件界面端统计各个缺陷出现的数量。在VM的界面模块,VM二次开发,或算子SDK开发中,对于获取这类参数都有相应的方法。VM算子SDK可以通过tool类下result获取类别图ClassMap,也可以通过ClassInfo获取指定的缺陷概率图SegmentMap,类别图的灰度值依次对应缺陷索引,可以更为自由的统计参数,且处理耗时很低。而二次开发根据模块方案的实例化得到模块结果,也可以对标签数据做类型转化,以实现统计的目的。最后界面操作上,则需要通过模块之间的相互组合实现功能,比较依赖软件版本开放的参数范围。
遇事不决,开始想办法。
本文先针对使用最多的界面层做方案讨论:
方案一:
1.多类别DL分割模块配对的blob标签分析,其结果中有对应的类别标签与标签值:

2.据“多类别分割任务下实现指定类别的阈值调整”篇中的方法,我们可以运用VM内多个blob模块,来获得各个缺陷类别在样本中的数量,位置,面积等参数,从变量计算模块中依次设置变量公式,以达到统计的目的。
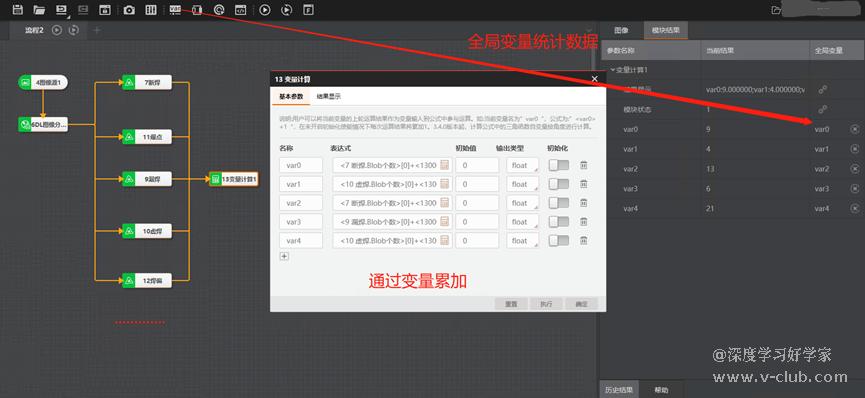
3.但是当遇到缺陷类别较多的情况下,需要拖出相同数量的blob分析模块,导致流程耗时倍增,这也是模块组件的局限,目前来看还需回到代码层解决。

方案二:
1.在VM逻辑工具中,有个脚本工具可以实现在VM内进行代码操作,能以订阅的方式拿到各个模块的参数数据,并在代码内进行参数操作。因此,可以在通过blob标签分析后接入脚本,在变量中获取标签值,类别标签名的索引值,blob个数等参数,对相同标签类别做遍历累加,在界面层实现快速、有效、和较为通用的统计功能。
 //----------//
//----------//
2.需订阅的模块参数如上图,其中标签值(result)会依次输出缺陷的灰度值(LabelIndex),类别标签(name)对应result的输出,Label代表该模型解析的类别名。
3.在流程Process函数下,创建字典类型Dictionary<int,string>,用于录入类别索引及类别名。
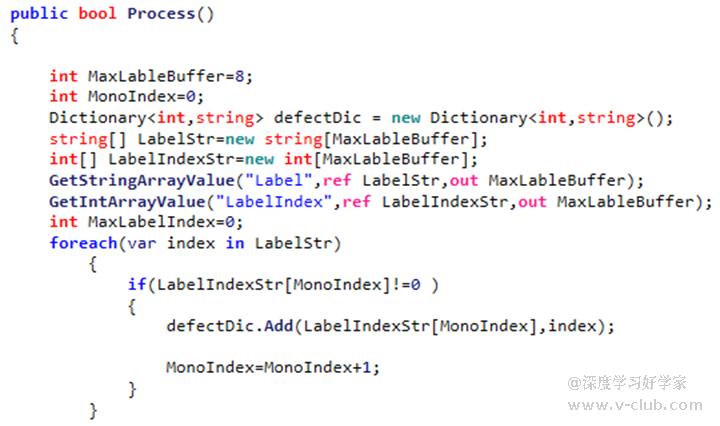
4.数组开辟的空间由索引最大值决定:

5.输出所需信息:

6.以上为完整处理流程,该方案耗时情况如下左图,示例效果如下右图。
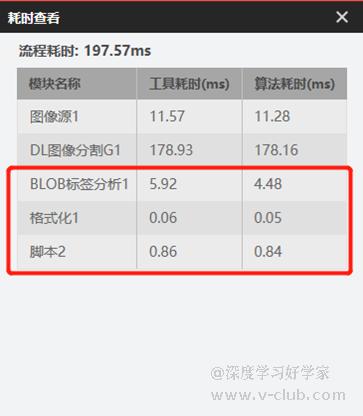

相比于前者方案,不会受限于因类别数量增加导致的耗时倍增问题,同时规避了类别索引乱序导致数组边界溢出,具有一定程度的通用性,代码功能比较简单,分享出来仅作参考。
版权声明:本文为V社区用户原创内容,转载时必须标注文章的来源(V社区),文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件至:v-club@hikrobotics.com 进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容。
上一篇
评论请先登录 登录

所属专题
相关阅读
 【形状匹配算法系列】从NCC到轮廓匹配:工业视觉的"定位之争",到底争的是什么?2026-05-19
【形状匹配算法系列】从NCC到轮廓匹配:工业视觉的"定位之争",到底争的是什么?2026-05-19 【技术分享】VM运行界面之清空图像2026-06-10
【技术分享】VM运行界面之清空图像2026-06-10 使用VM算法识别屏幕2026-06-05
使用VM算法识别屏幕2026-06-05 认证刷题与模拟考试系统2026-06-12
认证刷题与模拟考试系统2026-06-12- 移动机器人工程师培训与认证安排-26年6月2026-05-18
 浙公网安备 33010802013223号
浙公网安备 33010802013223号