


- 什么是深度学习?
- 深度学习的前沿研究与应用
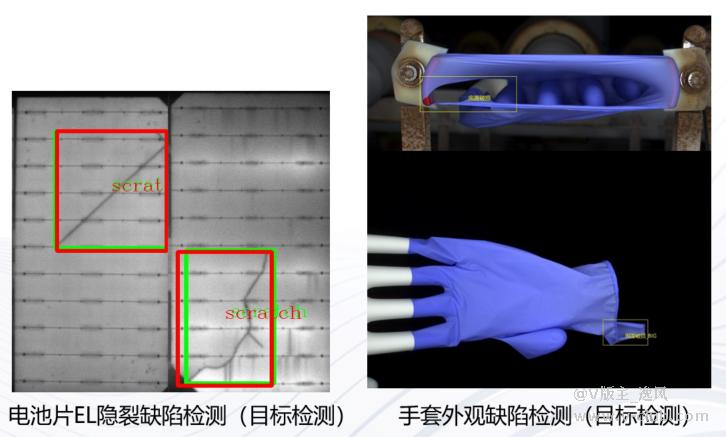
- 深度学习和传统算法在缺陷检测应用中的特点
- 深度学习训练工具VisionTrain1.4.1功能更新说明
- 模型优化方法---通用基础篇
- 模型优化方法---VM算法平台预测篇
- 模型优化方法---VisionTrain训练篇
- 模型优化方法---预测耗时篇
- 深度学习小工具之快速图像分割
- 深度学习小工具之标签转化工具
- 深度学习小工具之图像名称、标签文件内容修改工具
- 训练误差与泛化误差的关系
- 训练过程中对于误差值的理解
- 基本图像增强算法对深度学习模型结果的影响
- 使用VM深度学习功能实现模型训练与图像检索功能
- 智能相机-深度学习OCR训练及优化指南
- 一种提升OCR模型识别率的优化方法
- 根据实际需求找到最优方案-OCR识别篇
- 多分类分割任务下实现指定类别的阈值调整
- 多分类分割任务下的标注问题及解决思路
- 图像分割标注训练经验分享
- 基于VM界面层的多类别缺陷统计方案
- VM深度学习OCR项目经验分享
- 【VM集成开源AI】深度学习算子模块封装
- 深度学习推理耗时波动现象的解决方法
- 【共享学习】关于深度学习显卡推理那些事儿
- VM7100深度学习检测温度传感器焊点,裸针,锡珠,超盘,
- 深度学习缺陷检测项目经验分享
- 深度学习基础介绍
- 深度学习VS注册学习
深度学习缺陷检测项目经验分享
- 0
- 7
- 分享
- 2023-09-12 16:19
很多客户在使用VM深度学习做缺陷检测项目时会不知道该选择什么模块,目标检测、图像分割、无监督甚至图像分类都能做缺陷项目,该如何选择呢?本文分别介绍了这些模块的做缺陷应用的特点,帮忙大家理解这些模块从而进行快速选择!

目前很多缺陷检测任务中,由于缺陷形态多样、对比度低、种类多的难题,传统的缺陷检测算法往往无法有较高的识别率,越来越多的用户会采用深度学习算法去检测缺陷。
可做缺陷检测应用的模块:


图像分割特点:逐像素(精度高)、得到目标轮廓(可计算目标实际面积)
VM软件中图像分割模块会根据训练是否为多类别生成概率图及类别图,黑色灰度值为0的区域被认为是背景



目标检测特点:训练前会根据Patch大小对图片进行降采样,得到的结果为目标框(只能得到目前框的面积无法获取目标实际轮廓面积)


可以看到在训练过程中,无论选择那种Patch,缺陷的细节都存在一定损失。甚至选择小Patch的时候,边缘隐裂缺陷几乎看不见了

1、缺陷目标占比较小,选择图像分割,目标检测需目标占比大于1.31%才满足算法要求。
2、缺陷对比度较低,选择图像分割,目标检测针对缺陷灰度值与背景变化不大的场景,能力不如分割。
3、需要得到目标的实际轮廓面积,选择图像分割,目标检测只能获取到检测框的面积。
4、缺陷占比满足目标检测要求,且缺陷明显,形态较为固定,选择目标检测,打标比分割更简单(分割需要逐像素标定,目标检测只需要画框)。
(注:一般情况下能用目标检测做的缺陷项目,图像分割算法均也适用)

项目建议:大数量的计数项目建议采用图像分割去做(各目标形态类似)
1、若一张图片中的目标数较多,单个目标的占比自然会降低,占比越小目标检测效果会变差,故推荐图像分割;
2、图像分割可采用裁剪小图训练,预测大图预测,减少打标工作量。如下示例


图像分割常见误区:
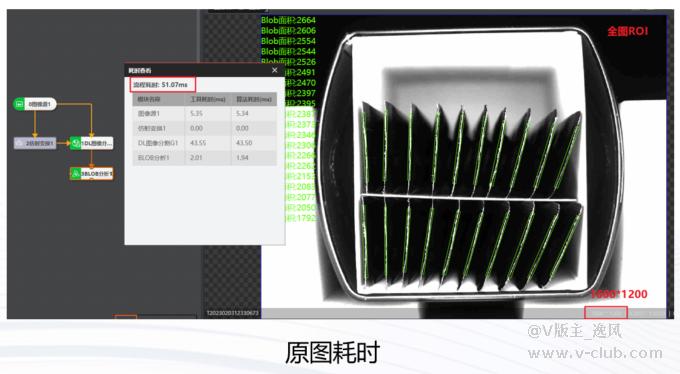
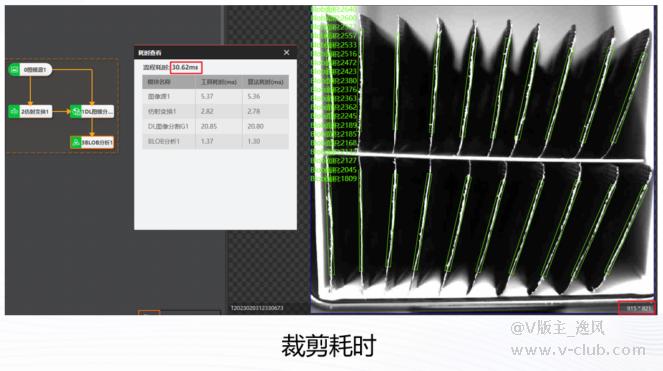
大家都知道对于图像分割来说,图像分辨率越大耗时越长。为了降低耗时,减少图像分辨率是一种常见的方式。在某些场景中检测物只占图像的一小部分,客户会通过画ROI的方式去降低耗时,这样做可以降低耗时吗?答案是否定的。在目前所有深度学习模块中,即使画了ROI也是全图做检测,只是通过ROI过滤掉了ROI外的检出的内容,所以想要降低耗时还是需要进行仿射变化做裁剪或者设置开窗等方式。
原图耗时:51.07ms
ROI耗时:53.43ms
裁剪耗时:30.62ms
目标检测常见误区:
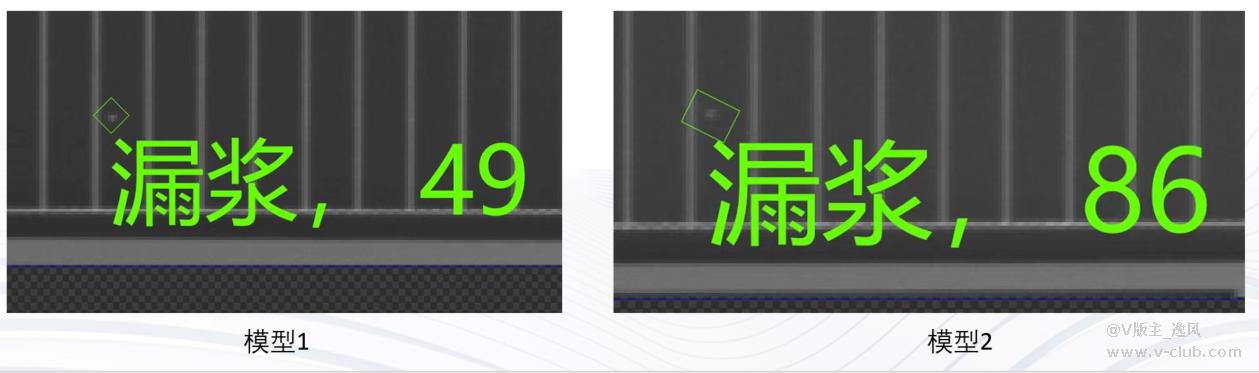
目标检测可以做高精度的定位抓取吗?答案是否定的。目标检测只可做初定位,如果要做精定位还是需要使用传统的定位算法。定位框的位置、大小都是随机波动的,且波动的大小不好把握,可能产品位置、亮度等因素发生了一定变化,训练集中此类样本较少,框的大小和位置的波动就会较大。所以一般情况下,只用目标检测做初定位。
衍生:其他的深度学习模块也是如此,比如图像分割,可能相同训练集训练出来的两个模型检测同一张图片缺陷的大小就不相同。如下图示例;以往的项目中,针对缺陷大小有要求的,一般都用深度学习先检测出来,然后再去判断缺陷大小,其实深度学习算法给出的目前大小的精度往往也是不高的,容易收到图像本身的干扰。所以针对一些高精度要求的项目深度学习算法是不合适的,深度学习算法更像一种定性的算法,而非定量。

首先需要了解是:图像分类与目标检测一样,在训练前会根据设置的Patch参数进行降采样。故如果用于区分OK和NG的特征较小,经过降采样后其差异会变得更小,导致无法区分

分类用于做缺陷的案例:



图像分类常见误区:
针对没有在训练集内的类别是否能够不给出类别或者当成“其他”类,答案是否定的,目前无法做到!
1、之前有进行过测试验证,想通过卡置信度的方式来对未训练的类别进行不分类,但是结果表明,部分可以进行过滤,但是还有一部分未训练的类别置信度非常高可能存在0.99999无法通过置信度进行过滤。
衍生:关于置信度的问题这边就又涉及到字符串中单个字符的置信度了,经常有字符缺陷的项目会咨询到是否可以通过单个字符的置信度去判断字符是否有缺陷呢,答案也是一样,某些严重缺陷的字符可能置信度会低,轻微缺陷置信度任会很高。毕竟深度学习算法本身就是往泛化性、兼容性去做提升,对于深度学习算法来说缺失一部分或者与训练有一些差异的情况任然能准确识别出来才是比较优质的算法。
2、关于训练成“其他类”之前也是做过验证,将一些不需要识别的类别训练成了其他类了。但是图像分类本身算法就是去提取训练图像的共同特征,“其他类”中的图像特征往往不统一,无法提取到共同特征,反而会对训练造成不良的影响。

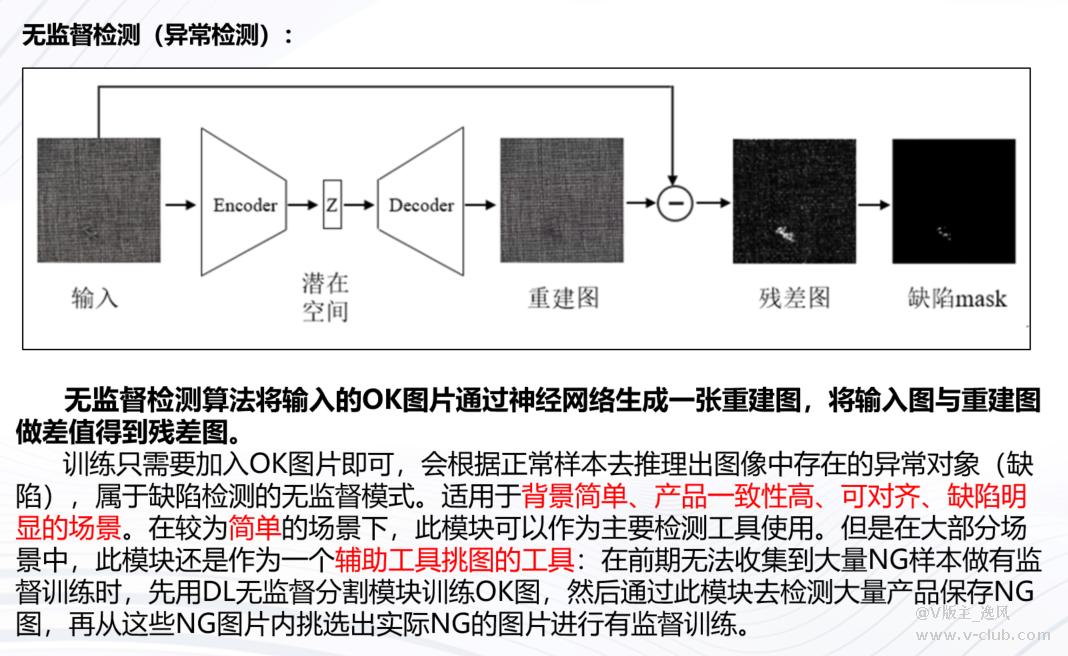
无监督检测与异常检测的区别:两个模块都是无监督检测算法,为不同研发部门编写,均只需训练OK图片即可检测NG图片。

异常检测模块检测生成的结果为残差图,白色255认为是背景,灰度值越低认为是缺陷的概率越大。无监督分割模块检测生成的为概率图(与图像分割一直,黑色灰度值0认为是背景,灰度值越高认为是缺陷的概率越大)


无监督算法应用场景:

算法要求:一致性高,产品可对齐; 缺陷明显;
总结:无监督算法的性能,不会超过有监督算法性能。目前市场上深度学习无监督算法总体看都不算太成熟,难以有较为高准去率及低误检的应用。如果客户要求识别率很高比如99.9%或者误检要求很低,建议采用有监督的方方式。

1、针对分类及无监督都可以做的项目,看看是否能够提供较多的NG图像,可以建议用分类,毕竟有监督的方式识别率肯定会被无监督的高。无法提供较多NG的图就可以采用无监督尝试,不需要NG样本这就是无监督的优势。
2、如果缺陷占比较小,且位置不固定,建议采用无监督,分类对这类缺陷要求位置较为固定,比如说字符缺陷检测。

3、如果需要显示缺陷位置,只能采用无监督。图像分类只能给出整张图片OK还是NG,无法给出具体的缺陷位置,而无监督可以。

4、无监督算法只能对缺陷进行定位无法进行分类,图像分类算法可进行分类。
通过以上内容的了解,相信大家对于缺陷检测项目方案的设计会更加准确。
版权声明:本文为V社区用户原创内容,转载时必须标注文章的来源(V社区),文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件至:v-club@hikrobotics.com 进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容。
上一篇
下一篇
评论请先登录 登录
全部评论 7


- 1

所属专题
相关阅读
 【形状匹配算法系列】从NCC到轮廓匹配:工业视觉的"定位之争",到底争的是什么?2026-05-19
【形状匹配算法系列】从NCC到轮廓匹配:工业视觉的"定位之争",到底争的是什么?2026-05-19 【技术分享】VM运行界面之清空图像2026-06-10
【技术分享】VM运行界面之清空图像2026-06-10 使用VM算法识别屏幕2026-06-05
使用VM算法识别屏幕2026-06-05 认证刷题与模拟考试系统2026-06-12
认证刷题与模拟考试系统2026-06-12- 移动机器人工程师培训与认证安排-26年6月2026-05-18
 浙公网安备 33010802013223号
浙公网安备 33010802013223号