


- 什么是深度学习?
- 深度学习的前沿研究与应用
- 深度学习和传统算法在缺陷检测应用中的特点
- 深度学习训练工具VisionTrain1.4.1功能更新说明
- 模型优化方法---通用基础篇
- 模型优化方法---VM算法平台预测篇
- 模型优化方法---VisionTrain训练篇
- 模型优化方法---预测耗时篇
- 深度学习小工具之快速图像分割
- 深度学习小工具之标签转化工具
- 深度学习小工具之图像名称、标签文件内容修改工具
- 训练误差与泛化误差的关系
- 训练过程中对于误差值的理解
- 基本图像增强算法对深度学习模型结果的影响
- 使用VM深度学习功能实现模型训练与图像检索功能
- 智能相机-深度学习OCR训练及优化指南
- 一种提升OCR模型识别率的优化方法
- 根据实际需求找到最优方案-OCR识别篇
- 多分类分割任务下实现指定类别的阈值调整
- 多分类分割任务下的标注问题及解决思路
- 图像分割标注训练经验分享
- 基于VM界面层的多类别缺陷统计方案
- VM深度学习OCR项目经验分享
- 【VM集成开源AI】深度学习算子模块封装
- 深度学习推理耗时波动现象的解决方法
- 【共享学习】关于深度学习显卡推理那些事儿
- VM7100深度学习检测温度传感器焊点,裸针,锡珠,超盘,
- 深度学习缺陷检测项目经验分享
- 深度学习基础介绍
- 深度学习VS注册学习
VM深度学习OCR项目经验分享
- 0
- 2
- 分享
- 2023-05-26 16:41
从OCR项目的可行性、算法模块选择、训练参数选择、算法资源占用、常见误区等方面给大家做一些分享
一、判断项目可行性
以肉眼去查看图像内的字符:
1、人眼很容易看清,算法效果会较好,识别率会较高,一般可以保证三、四个9的识别率。
2、人眼较难分清,但放大仔细看可以分清,难度较大,识别率难以保证,但是可以尝试,算法也许能做得比人眼更好。
3、人眼无法分清,无可行性,PASS。 ---> 尝试用预处理的方式去提升字符对比度,或者改善硬件成像,都无法做到,直接拒绝项目

如果属于肉眼可分辨,那再判断是否需要识别中文或者其它国家的语言(注:目前海康深度学习算法不支持中文识别,需要使用其它方式去判断)
•如果所需识别大量的文中或其他特殊语言的字符,目前算法版本无法实现,PASS
•只需要识别少量中文或者特殊语言,打标过程中可以使用一些固定的(实际文本行中不会出现的)字符或者符号去代替这些少量的中文或者特殊语言。然后在脚本中将这些固定字符替换成实际的字符。

二、采用何种算法去完成项目
采用传统定位方式:模板匹配或者Blob用的较多
一:传统方式直接匹配字符
二:匹配产品的某个固定特征,后面加上位置修正,字符识别模块手动画ROI订阅位置修正关系

如上图方案,通过匹配“合格”,后面加上位置修正,字符识别模块手动画ROI订阅位置修正关系。要求:1、“合格”特征稳定,能被准确匹配 2、“合格”与需被识别的字符位置关系固定
三:直接画一个稍大于字符的固定ROI

如上图,DL字符识别直接画一个稍大一些的ROI,直接识别要求:1、字符位置波动小,不会超出画的ROI 2、打标的时候也需要将框标记的大一些,和预测的框保持一致。
采用深度学习定位方式:特征不稳定,字符位置波动较大,需要采用深度学习字符定位的方式
一、字符占比满足字符的高度/图像分辨率宽高较大者>12/528,字符可定位成功
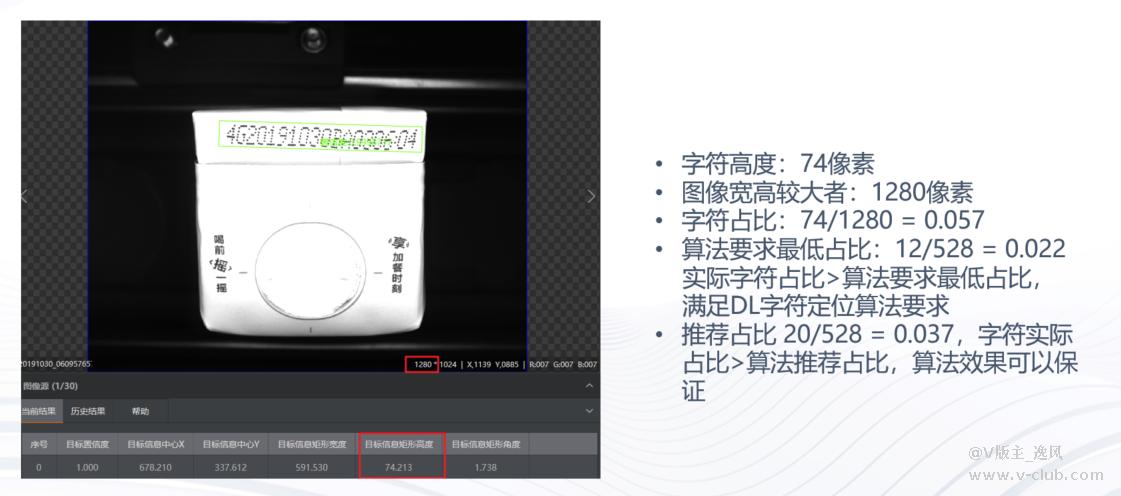
二、不满足一的要求,字符占比整张图像较小。需要对图像进行裁剪,提高字符的占比后,再采用深度学习字符定位。若无法进行裁剪满足要求,PASS

裁剪要求(常见误区):尽可能保持裁剪图像分辨率一致
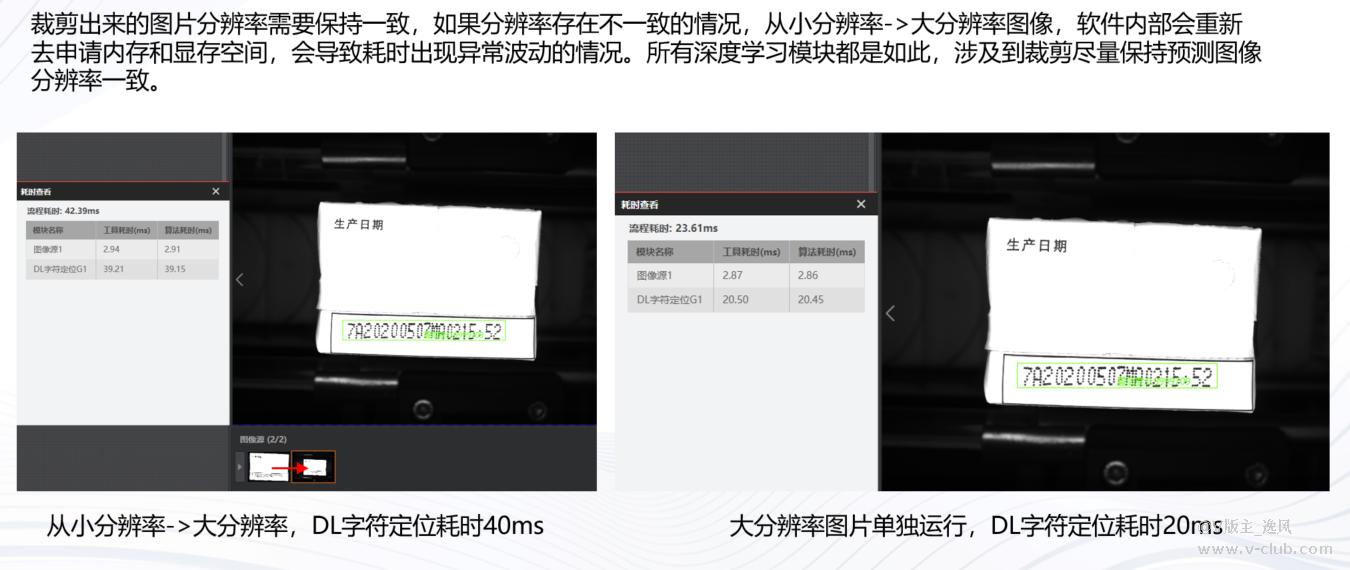
字符识别一般都推荐采用深度学习算法!
三、模式选择:
字符识别项目分两种模式:
一:文本行模式 ,需训练两个模型,文本定位模型 + 文本行识别模型
二:单字符模式 ,只需训练 单字符检测模型
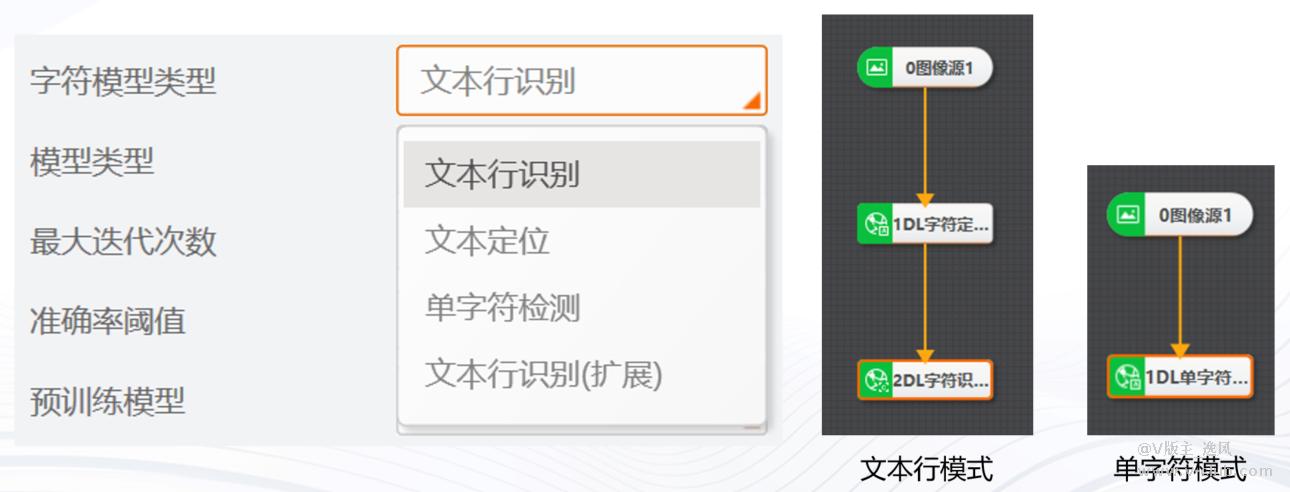
文本行模式应用场景:单行水平字符、标准多行水平字符
单字符模式应用场景:单个字符(1~2个字符)、不规整字符、环形无法展开字符
特殊情况:
一:环形可展开字符:针对在圆环上的字符,建议先对圆环检展开,后用文本行算法去做检测。与单字符相比可节省很多打标的工作量。

二、同一张图片中既有文本行也有单个字符需要识别:正常情况下应该分成两个模型训练,为了方便可以都采用文本行的方式,但是单个字符采用文本行的方式需要将框宽度拉长,要远远大于高度,否则角度会错误

四、深度学习训练参数选择
1、VisionTrain中的字符识别有两种算法,文本行识别及文本行识别拓展

两种模式的对比: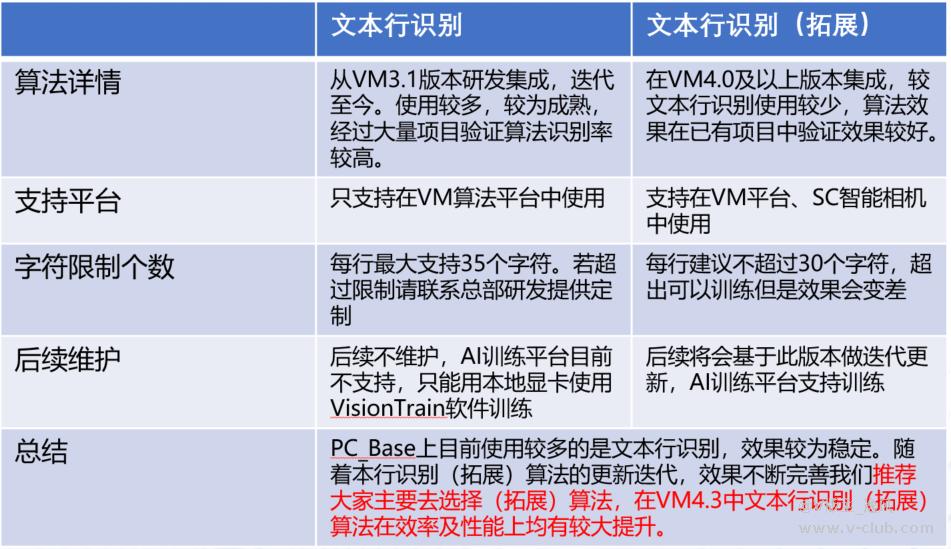
CPU及GPU预测平台能力:

资源消耗及性能对比:
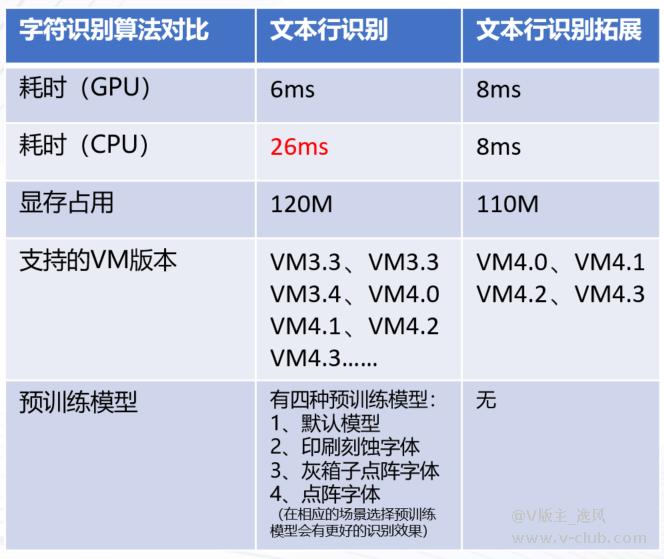
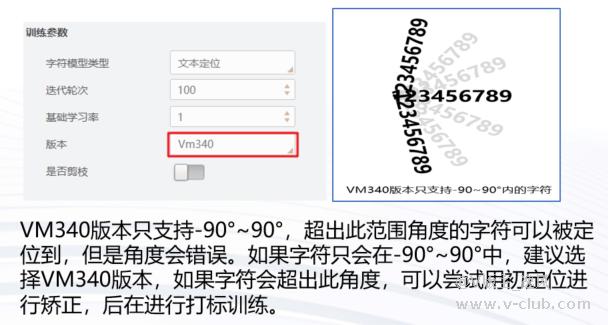
2、VisionTrain中字符定位有较多的版本,其中比较关键的版本为VM340及之前版本,VM400两个大类

常见误区:VM4.3版本一定得用VM430模型,VM4.0就一定得用VM400模型,VM3.4就一定得用VM340模型? 答案是否!
版本兼容性问题:并不是说320版本只能在VM3.2上使用,可以在更高版本如VM4.2、VM4.3上使用,VM高版本可以兼容低版本的模型。但是高版本的模型不可在低版本VM中使用,如VM400版本模型不可在低版本VM3.4中使用。版本选择需根据实际项目情况来选择,如下示例:
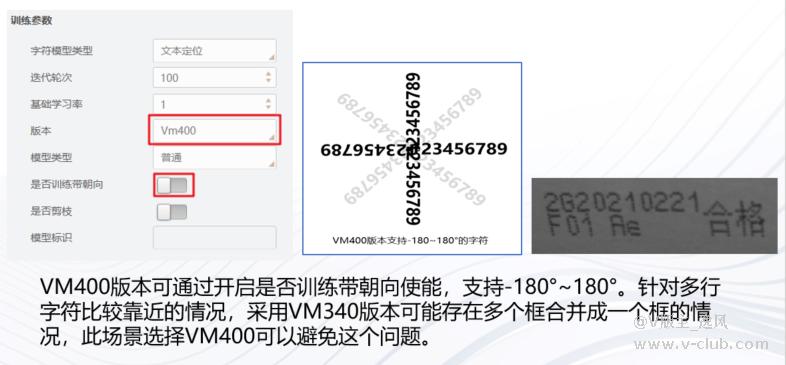
资源消耗及性能对比: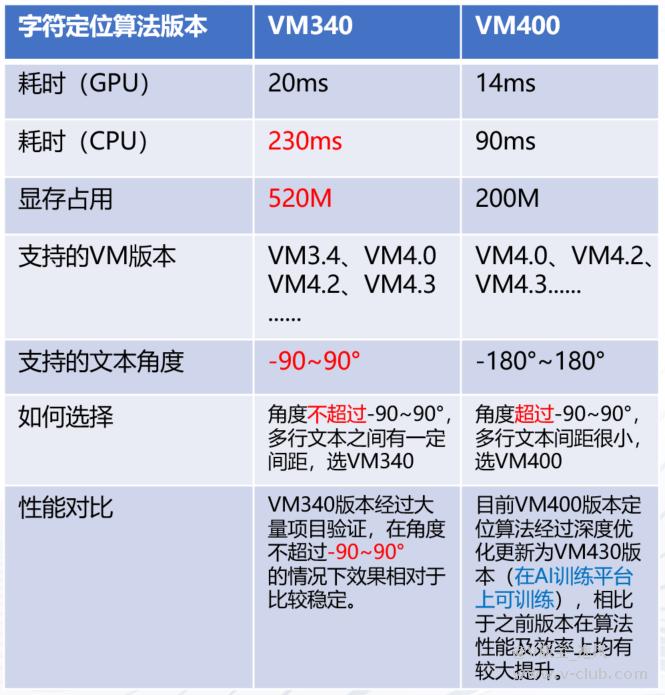
五、常见误区
1、字符识别是否没有训练过的字符就一定识别不出吗,答案是否定的!
如下图用一张图片复制11张进行训练,未包含字符6与7,在下方预测的图片中,6识别正确,7识别错误。所有字符识别的训练都可以理解为增量训练,在原本的一个基础库上去做增量训练,故训练样本中没有的字符但是基础库中存在还是有可能会识别正确。

但是为何7会识别错误呢,因为增量训练会着重训练新增的样本,会弱化模型之前学习的内容。可以理解为网络总大小固定,当有新的图片加入训练后,需要将之前的内容遗忘一些才能记住新训练的内容,故还是建议训练集需包含所有会出现的字符。
2、是否训练集中需出现和需要识别的实际字符一样的字符串才可以被正确识别,答案是否定的!
比如训练集中只训练了20220003,组合顺序发生了变化变成了32332220同样会被识别正确。只要这个字符在文本行的任意位置出现过,就会被学习到,可以理解为文本行训练任然是单个单个字符去训练学习的。
3、字符靠近边缘,没有被定为到,模型效果不行?答案不一定!
需要关闭DL字符定位模块的边缘使能看看,可能是因为框出边界被过滤掉了(注:目标检测模块和字符定位一样,默认边缘筛选使能开启,如果检测目标靠近边缘或者ROI边缘同样可能会被过滤。)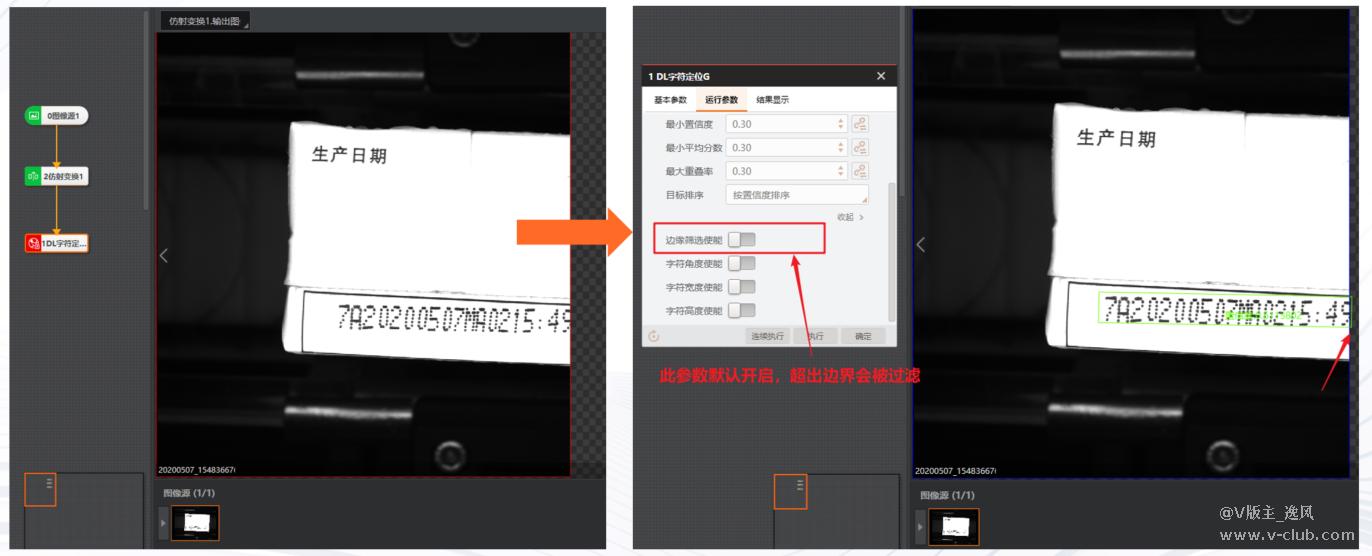
版权声明:本文为V社区用户原创内容,转载时必须标注文章的来源(V社区),文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件至:v-club@hikrobotics.com 进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容。
上一篇
下一篇
评论请先登录 登录
全部评论 2

- 1

所属专题
相关阅读
 【形状匹配算法系列】从NCC到轮廓匹配:工业视觉的"定位之争",到底争的是什么?2026-05-19
【形状匹配算法系列】从NCC到轮廓匹配:工业视觉的"定位之争",到底争的是什么?2026-05-19 项目实施过程中关于对标的思路及经验分享2026-05-09
项目实施过程中关于对标的思路及经验分享2026-05-09- 移动机器人常识2026-05-15
 通过socket将图片传输到vm外部2026-05-09
通过socket将图片传输到vm外部2026-05-09- 移动机器人技术分享-26年5月2026-05-15
 浙公网安备 33010802013223号
浙公网安备 33010802013223号