一. 开发环境
1. 网络模型训练环境
(1)Python 3.7.4
(2)pytorch 1.13.1
2. 模型部署环境
(1)visual studio 2022
(2)OpenCV 4.8.0
(3)libtorch 1.13.1
二.数据采集
使用MV-DB500S-A相机对锤子、扳手、剪刀等工具物品进行RGB图像以及深度图的采集和保存。该步骤结合Mv3dRgbdSDK实现相机软触发图像采集和保存,相关代码如下:
#include "../common/common.hpp"
#include <iostream>
#include <string>
#include <sstream>
void __stdcall CallBackFunc(MV3D_RGBD_FRAME_DATA* pstFrameData, void* pUser)
{
if (NULL != pstFrameData)
{
MV3D_RGBD_IMAGE_DATA img_depth = pstFrameData->stImageData[0];
if (ImageType_Depth == img_depth.enImageType)
{
uint32_t n_0 = img_depth.nFrameNum;
LOG("current frame 0 num : %d", n_0);
std::stringstream ss;
std::string str;
ss << n_0;
ss >> str;
std::string savename = "./saved/depth/" + str;
ASSERT_OK(MV3D_RGBD_SaveImage(pUser, &img_depth, FileType_TIFF, savename.c_str()));
// process depth data
MV3D_RGBD_IMAGE_DATA stPointCloudImage;
ASSERT_OK(MV3D_RGBD_MapDepthToPointCloud(pUser, &img_depth, &stPointCloudImage));
savename = "./saved/pointCloud/" + str;
ASSERT_OK(MV3D_RGBD_SavePointCloudImage(pUser,&stPointCloudImage, PointCloudFileType_PLY, savename.c_str()));
MV3D_RGBD_IMAGE_DATA img_RGB = pstFrameData->stImageData[1];
if (ImageType_RGB8_Planar == img_RGB.enImageType)
{
savename = "./saved/RGB/" + str;
ASSERT_OK(MV3D_RGBD_SaveImage(pUser, &img_RGB, FileType_BMP, savename.c_str()));
}
else
{
printf("wrong frame data : 1 is not RGB8 type \n");
}
LOG("saved: %d", n_0);
}
else
{
printf("wrong frame data : 0 is not Depth type \n");
}
}
else
{
LOGD("pstFrameData is null!\r\n");
}
}
int main()
{
MV3D_RGBD_VERSION_INFO stVersion;
ASSERT_OK(MV3D_RGBD_GetSDKVersion(&stVersion));
LOGD("dll version: %d.%d.%d", stVersion.nMajor, stVersion.nMinor, stVersion.nRevision);
ASSERT_OK(MV3D_RGBD_Initialize());
unsigned int nDevNum = 0;
ASSERT_OK(MV3D_RGBD_GetDeviceNumber(DeviceType_Ethernet | DeviceType_USB, &nDevNum));
LOGD("MV3D_RGBD_GetDeviceNumber success! nDevNum:%d.", nDevNum);
ASSERT(nDevNum);
// 查找设备
std::vector<MV3D_RGBD_DEVICE_INFO> devs(nDevNum);
ASSERT_OK(MV3D_RGBD_GetDeviceList(DeviceType_Ethernet | DeviceType_USB, &devs[0], nDevNum, &nDevNum));
for (unsigned int i = 0; i < nDevNum; i++)
{
if (DeviceType_Ethernet == devs[i].enDeviceType)
{
LOG("Index[%d]. SerialNum[%s] IP[%s] name[%s].\r\n", i, devs[i].chSerialNumber, devs[i].SpecialInfo.stNetInfo.chCurrentIp, devs[i].chModelName);
}
else if (DeviceType_USB == devs[i].enDeviceType)
{
LOG("Index[%d]. SerialNum[%s] UsbProtocol[%d] name[%s].\r\n", i, devs[i].chSerialNumber, devs[i].SpecialInfo.stUsbInfo.enUsbProtocol, devs[i].chModelName);
}
}
//打开设备
void* handle = NULL;
unsigned int nIndex = 0;
ASSERT_OK(MV3D_RGBD_OpenDevice(&handle, &devs[nIndex]));
LOGD("OpenDevice success.");
// --- param
//MV3D_RGBD_ExportAllParam(handle, "./mParam.txt");
ASSERT_OK(MV3D_RGBD_ImportAllParam(handle, "./mParam.txt"));
// ---
ASSERT_OK(MV3D_RGBD_RegisterFrameCallBack(handle, CallBackFunc, handle));
// 开始工作流程
ASSERT_OK(MV3D_RGBD_Start(handle));
LOGD("Start work success.");
// ---
bool is_run = true;
int ch;
printf("Please enter the action to be performed:\n");
printf("[q] Exit [c] capture one frame \n");
while (is_run)
{
if (_kbhit())
{
ch = _getch();
switch (ch)
{
case 'q':
case 'Q':
is_run = false;
break;
case 'c':
case 'C':
ASSERT_OK(MV3D_RGBD_SoftTrigger(handle));
break;
default:
LOGD("Unmapped key %d", ch);
break;
}
}
}
ASSERT_OK(MV3D_RGBD_Stop(handle));
ASSERT_OK(MV3D_RGBD_CloseDevice(&handle));
ASSERT_OK(MV3D_RGBD_Release());
LOGD("Main done!");
return 0;
}
基于上述代码程序采集到的图像如下,图2.1为 RGB 图,图2.2为对应深度图。
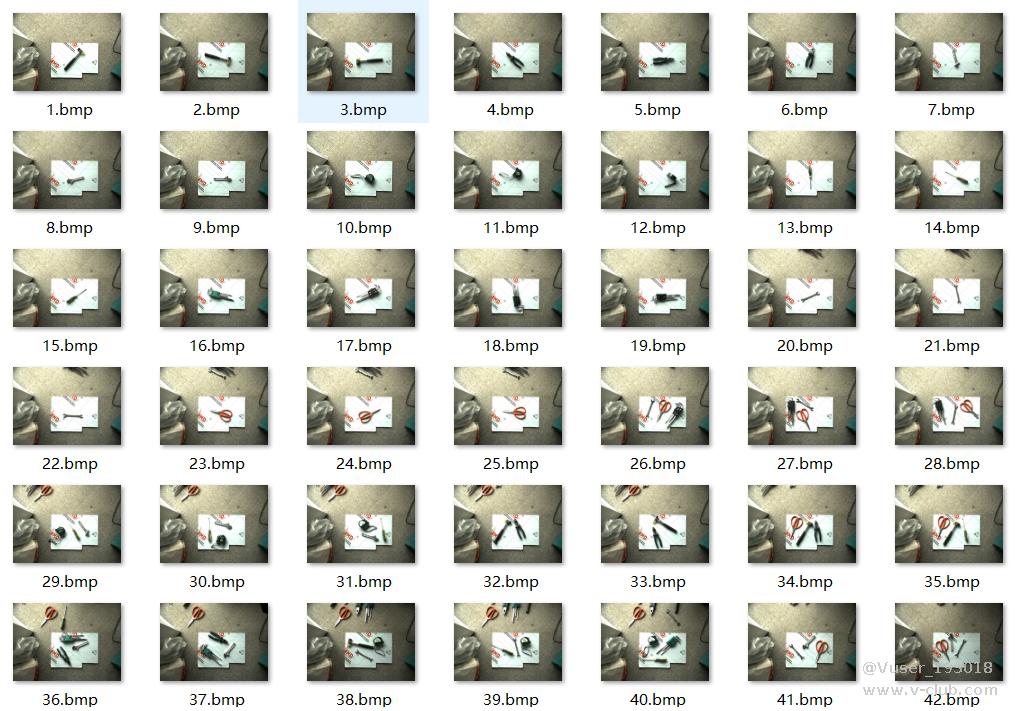
图2.1 RGB 图

图2.2 深度图
三. YOLO模型训练及部署
1. 数据标注及训练
YOLO 模型使用 RGB 图像进行标注训练,标注工具使用 labelimg,标注过程如图3.1所示
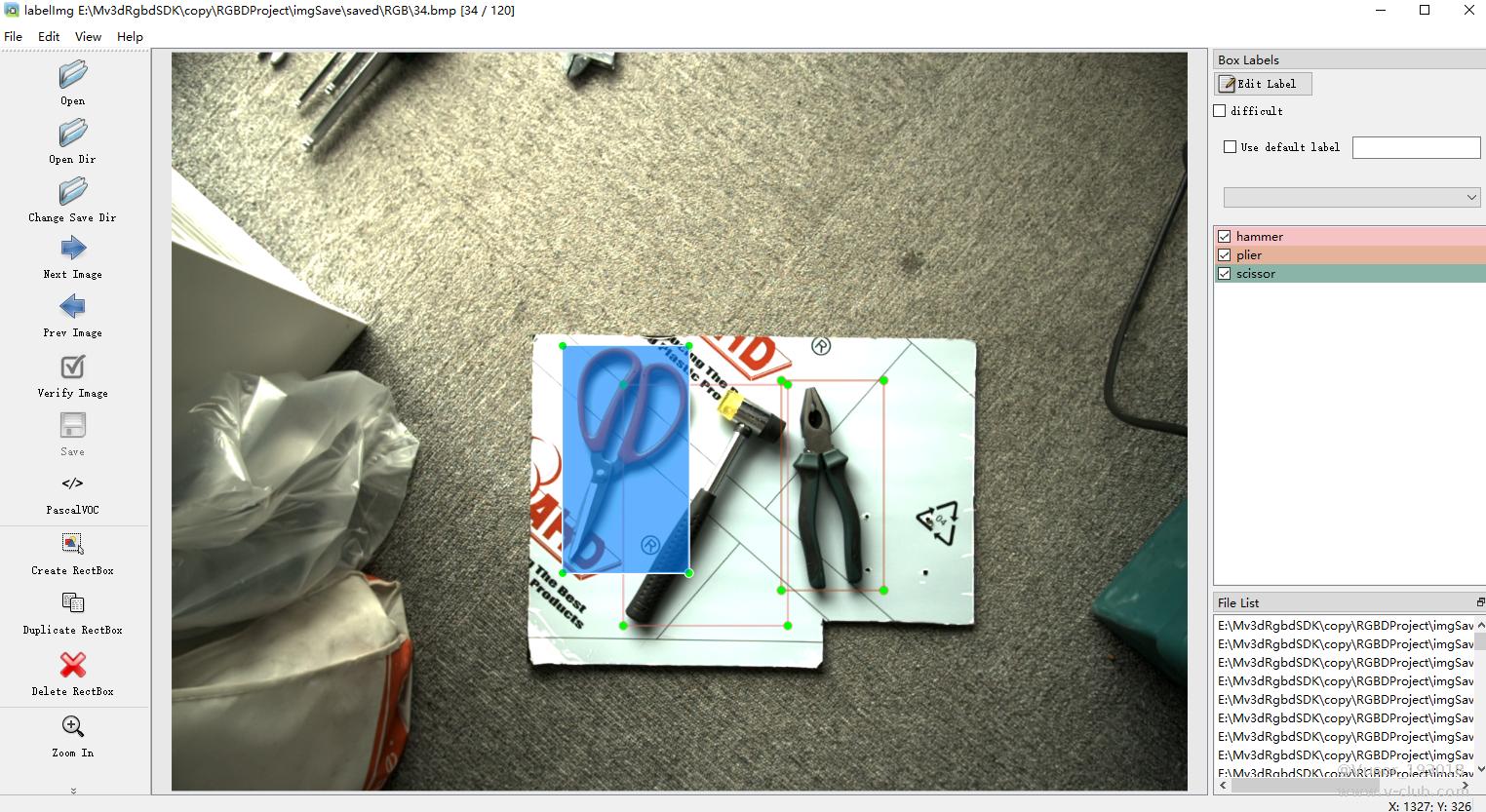
图3.1 使用 labelimh 标注矩形框
完成上述图片标注后,将数据集进行拆分并进行模型训练,本课题使用的目标检测模型为YOLOv5, 详见 https://github.com/ultralytics/yolov5
2. 模型部署
基于 libtorch 将训练好的目标检测模型进行部署,对所有图像中的工具对象进行检测,并将RGB图以及对应深度裁剪下来用于后续的平面抓取模型的标注训练,相关代码如下:
封装 YOLOv5Handle 类。
YOLOv5Handle.h
#pragma once
#include <iostream>
#include <torch/csrc/api/include/torch/torch.h>
#include <c10/core/TensorImpl.h>
#include <torch/csrc/autograd/grad_mode.h>
#include <torch/script.h>
#include <opencv2/core/core.hpp>
#include <opencv2/highgui/highgui_c.h>
#include <opencv2/highgui/highgui.hpp>
#include <opencv2/imgproc/imgproc.hpp>
#include <opencv2/dnn.hpp>
#include <time.h>
#include <string>
#include <chrono>
#include <cmath>
#include <sstream>
struct Detection
{
cv::Rect bbox;
float score;
int class_idx;
};
class YOLOv5Handle
{
public:
YOLOv5Handle(std::string model_path);
std::vector<std::vector<Detection>> predect(cv::Mat data_in);
private:
// variables
torch::DeviceType device_type;
torch::jit::script::Module module;
enum Det
{
tl_x = 0,
tl_y = 1,
br_x = 2,
br_y = 3,
score = 4,
class_idx = 5
};
// functions
std::vector<float> LetterboxImage(const cv::Mat& src, cv::Mat& dst, const cv::Size& out_size);
torch::Tensor xywh2xyxy(const torch::Tensor& x);
void Tensor2Detection(const at::TensorAccessor<float, 2>& offset_boxes,
const at::TensorAccessor<float, 2>& det,
std::vector<cv::Rect>& offset_box_vec,
std::vector<float>& score_vec);
void ScaleCoordinates(std::vector<Detection>& data, float pad_w, float pad_h,
float scale, const cv::Size& img_shape);
std::vector<std::vector<Detection>> PostProcessing(const torch::Tensor& detections,
float pad_w, float pad_h, float scale, const cv::Size& img_shape,
float conf_thres, float iou_thres);
};
YOLOv5Handle.cpp
#include "YOLOv5Handle.h"
YOLOv5Handle::YOLOv5Handle(std::string model_path)
{
// 0. check GPU
bool is_available = torch::cuda::is_available();
if (false == is_available)
{
std::cout << "cuda::is_available():" << is_available << std::endl;
}
// 1. init module
device_type = torch::kCPU;
torch::Device device(device_type);
module = torch::jit::load(model_path);
module.to(device);
//module.to(torch::kHalf);
module.eval();
}
std::vector<std::vector<Detection>> YOLOv5Handle::predect(cv::Mat data_in)
{
cv::Mat img_input = data_in.clone();
std::vector<float> pad_info = LetterboxImage(img_input, img_input, cv::Size(640, 640));
//cv::imshow("img_input", img_input);
//cv::waitKey(0);
//cv::destroyAllWindows();
const float pad_w = pad_info[0];
const float pad_h = pad_info[1];
const float scale = pad_info[2];
cv::cvtColor(img_input, img_input, cv::COLOR_BGR2RGB);
//归一化需要是浮点类型
img_input.convertTo(img_input, CV_32FC3, 1.0f / 255.0f); // normalization 1/255
// 加载图像到设备
auto tensor_img = torch::from_blob(img_input.data, { 1, img_input.rows, img_input.cols, img_input.channels() }).to(device_type);
// BHWC -> BCHW
tensor_img = tensor_img.permute({ 0, 3, 1, 2 }).contiguous(); // BHWC -> BCHW (Batch, Channel, Height, Width)
//tensor_img = tensor_img.to(torch::kHalf);
std::vector<torch::jit::IValue> inputs;
torch::NoGradGuard no_grad;
// 在容器尾部添加一个元素,这个元素原地构造,不需要触发拷贝构造和转移构造
inputs.emplace_back(tensor_img.to(device_type));
torch::jit::IValue output = module.forward(inputs);
auto detections = output.toTuple()->elements()[0].toTensor();
// set up threshold
float conf_thres = 0.25;
float iou_thres = 0.6;
return PostProcessing(detections, pad_w, pad_h, scale, data_in.size(), conf_thres, iou_thres);
}
std::vector<float> YOLOv5Handle::LetterboxImage(const cv::Mat& src, cv::Mat& dst, const cv::Size& out_size)
{
auto in_h = static_cast<float>(src.rows);
auto in_w = static_cast<float>(src.cols);
float out_h = out_size.height;
float out_w = out_size.width;
float scale = std::min(out_w / in_w, out_h / in_h);
int mid_h = static_cast<int>(in_h * scale);
int mid_w = static_cast<int>(in_w * scale);
cv::resize(src, dst, cv::Size(mid_w, mid_h));
int top = (static_cast<int>(out_h) - mid_h) / 2;
int down = (static_cast<int>(out_h) - mid_h + 1) / 2;
int left = (static_cast<int>(out_w) - mid_w) / 2;
int right = (static_cast<int>(out_w) - mid_w + 1) / 2;
cv::copyMakeBorder(dst, dst, top, down, left, right, cv::BORDER_CONSTANT, cv::Scalar(114, 114, 114));
std::vector<float> pad_info{ static_cast<float>(left), static_cast<float>(top), scale };
return pad_info;
}
torch::Tensor YOLOv5Handle::xywh2xyxy(const torch::Tensor& x)
{
auto y = torch::zeros_like(x);
// convert bounding box format from (center x, center y, width, height) to (x1, y1, x2, y2)
y.select(1, Det::tl_x) = x.select(1, 0) - x.select(1, 2).div(2);
y.select(1, Det::tl_y) = x.select(1, 1) - x.select(1, 3).div(2);
y.select(1, Det::br_x) = x.select(1, 0) + x.select(1, 2).div(2);
y.select(1, Det::br_y) = x.select(1, 1) + x.select(1, 3).div(2);
return y;
}
void YOLOv5Handle::Tensor2Detection(const at::TensorAccessor<float, 2>& offset_boxes, const at::TensorAccessor<float, 2>& det, std::vector<cv::Rect>& offset_box_vec, std::vector<float>& score_vec)
{
for (int i = 0; i < offset_boxes.size(0); i++) {
offset_box_vec.emplace_back(
cv::Rect(cv::Point(offset_boxes[i][Det::tl_x], offset_boxes[i][Det::tl_y]),
cv::Point(offset_boxes[i][Det::br_x], offset_boxes[i][Det::br_y]))
);
score_vec.emplace_back(det[i][Det::score]);
}
}
void YOLOv5Handle::ScaleCoordinates(std::vector<Detection>& data, float pad_w, float pad_h, float scale, const cv::Size& img_shape)
{
auto clip = [](float n, float lower, float upper)
{
return std::max(lower, std::min(n, upper));
};
std::vector<Detection> detections;
for (auto& i : data) {
float x1 = (i.bbox.tl().x - pad_w) / scale; // x padding
float y1 = (i.bbox.tl().y - pad_h) / scale; // y padding
float x2 = (i.bbox.br().x - pad_w) / scale; // x padding
float y2 = (i.bbox.br().y - pad_h) / scale; // y padding
x1 = clip(x1, 0, img_shape.width);
y1 = clip(y1, 0, img_shape.height);
x2 = clip(x2, 0, img_shape.width);
y2 = clip(y2, 0, img_shape.height);
i.bbox = cv::Rect(cv::Point(x1, y1), cv::Point(x2, y2));
}
}
std::vector<std::vector<Detection>> YOLOv5Handle::PostProcessing(const torch::Tensor& detections, float pad_w, float pad_h, float scale, const cv::Size& img_shape, float conf_thres, float iou_thres)
{
/***
* 结果纬度为batch index(0), top-left x/y (1,2), bottom-right x/y (3,4), score(5), class id(6)
* 13*13*3*(1+4)*80
*/
constexpr int item_attr_size = 5;
int batch_size = detections.size(0);
// number of classes, e.g. 80 for coco dataset
auto num_classes = detections.size(2) - item_attr_size;
// get candidates which object confidence > threshold
auto conf_mask = detections.select(2, 4).ge(conf_thres).unsqueeze(2);
std::vector<std::vector<Detection>> output;
output.reserve(batch_size);
// iterating all images in the batch
for (int batch_i = 0; batch_i < batch_size; batch_i++) {
// apply constrains to get filtered detections for current image
auto det = torch::masked_select(detections[batch_i], conf_mask[batch_i]).view({ -1, num_classes + item_attr_size });
// if none detections remain then skip and start to process next image
if (0 == det.size(0)) {
continue;
}
// compute overall score = obj_conf * cls_conf, similar to x[:, 5:] *= x[:, 4:5]
det.slice(1, item_attr_size, item_attr_size + num_classes) *= det.select(1, 4).unsqueeze(1);
// box (center x, center y, width, height) to (x1, y1, x2, y2)
torch::Tensor box = xywh2xyxy(det.slice(1, 0, 4));
// [best class only] get the max classes score at each result (e.g. elements 5-84)
std::tuple<torch::Tensor, torch::Tensor> max_classes = torch::max(det.slice(1, item_attr_size, item_attr_size + num_classes), 1);
// class score
auto max_conf_score = std::get<0>(max_classes);
// index
auto max_conf_index = std::get<1>(max_classes);
max_conf_score = max_conf_score.to(torch::kFloat).unsqueeze(1);
max_conf_index = max_conf_index.to(torch::kFloat).unsqueeze(1);
// shape: n * 6, top-left x/y (0,1), bottom-right x/y (2,3), score(4), class index(5)
det = torch::cat({ box.slice(1, 0, 4), max_conf_score, max_conf_index }, 1);
// for batched NMS
constexpr int max_wh = 4096;
auto c = det.slice(1, item_attr_size, item_attr_size + 1) * max_wh;
auto offset_box = det.slice(1, 0, 4) + c;
std::vector<cv::Rect> offset_box_vec;
std::vector<float> score_vec;
// copy data back to cpu
auto offset_boxes_cpu = offset_box.cpu();
auto det_cpu = det.cpu();
const auto& det_cpu_array = det_cpu.accessor<float, 2>();
// use accessor to access tensor elements efficiently
Tensor2Detection(offset_boxes_cpu.accessor<float, 2>(), det_cpu_array, offset_box_vec, score_vec);
// run NMS
std::vector<int> nms_indices;
cv::dnn::NMSBoxes(offset_box_vec, score_vec, conf_thres, iou_thres, nms_indices);
std::vector<Detection> det_vec;
for (int index : nms_indices) {
Detection t;
const auto& b = det_cpu_array[index];
t.bbox =
cv::Rect(cv::Point(b[Det::tl_x], b[Det::tl_y]),
cv::Point(b[Det::br_x], b[Det::br_y]));
t.score = det_cpu_array[index][Det::score];
t.class_idx = det_cpu_array[index][Det::class_idx];
det_vec.emplace_back(t);
}
ScaleCoordinates(det_vec, pad_w, pad_h, scale, img_shape);
// save final detection for the current image
output.emplace_back(det_vec);
} // end of batch iterating
return output;
}
调用 YOLOv5Handle 类,实现目标检测以及图像裁剪
// YOLOv5.cpp : 此文件包含 "main" 函数。程序执行将在此处开始并结束。
//
#include "YOLOv5Handle.h"
int main()
{
YOLOv5Handle m_yolo("./models/best.torchscript");
int save_i = 0;
for (int i = 1; i < 101; i++)
{
std::stringstream ss;
ss << i;
std::string s;
ss >> s;
cv::String imr_path = "E:/Mv3dRgbdSDK/copy/RGBDProject/imgSave/saved/RGB/" + s + ".bmp";
cv::Mat imr = cv::imread(imr_path, -1);
cv::String imd_path = "E:/Mv3dRgbdSDK/copy/RGBDProject/imgSave/saved/depth/" + s + ".tiff";
cv::Mat imd = cv::imread(imd_path, -1);
std::vector<std::vector<Detection>> result = m_yolo.predect(imr);
for (int j = 0; j < result.size(); j++)
{
std::vector<Detection> res = result[j];
for (int m = 0; m < res.size(); m++)
{
Detection det = res[m];
std::cout << "BOX:" << det.bbox << " SCORE:" << det.score << " CLASSID:" << det.class_idx << std::endl;
//cv::rectangle(img, det.bbox, cv::Scalar(255, 255, 0));
cv::Mat imr_cut = imr(det.bbox).clone();
cv::Mat imd_cut = imd(det.bbox).clone();
cv::Mat imr_300;
cv::Mat imd_300;
cv::resize(imr_cut, imr_300, cv::Size(300, 300));
cv::resize(imd_cut, imd_300, cv::Size(300, 300));
std::stringstream ss1;
ss1 << save_i;
std::string s1;
ss1 >> s1;
cv::String save_r = "./cutted/" + s1 + "r.png";
cv::imwrite(save_r, imr_300);
cv::String save_d = "./cutted/" + s1 + "d.tiff";
cv::imwrite(save_d, imd_300);
save_i++;
}
}
}
}
基于上述代码程序保存的 RGB 图,以及对应深度图如图3.2所示

图3.2 基于YOLO预测后的裁剪图
四. GGCNN 平面抓取模型训练及部署
1. 数据标注及训练
基于上述裁剪的图像,使用 RGB 图 进行标注,标注过程如图4.1所示
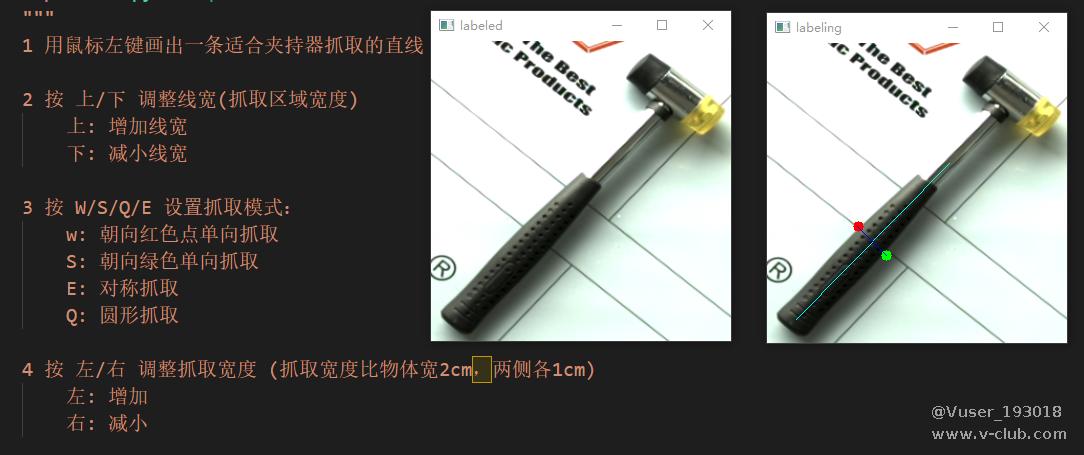
图4.1 抓取标注
本课题使用 GGCNN 平面抓取网络进行训练,GGCNN 的网络结构如图4.2 所示,网络信息详见 https://github.com/dougsm/ggcnn
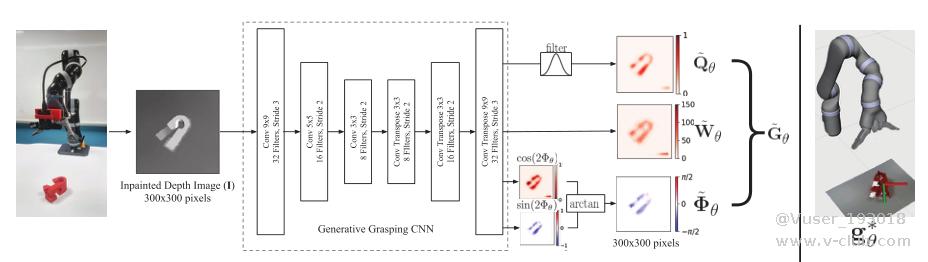
图4.2 GGCNN 网络结构
2. 模型部署
使用 libtorch 对抓取模型进行部署,代码如下
封装 GGCNNHandle 类
GGCNNHandle.h
#pragma once
#include <iostream>
#include <torch/csrc/api/include/torch/torch.h>
#include <c10/core/TensorImpl.h>
#include <torch/csrc/autograd/grad_mode.h>
#include <torch/script.h>
#include <opencv2/core/core.hpp>
#include <opencv2/highgui/highgui_c.h>
#include <opencv2/highgui/highgui.hpp>
#include <opencv2/imgproc/imgproc.hpp>
#include <time.h>
#include <string>
#include <chrono>
#include <cmath>
struct GGCNNresults
{
cv::Point p;
float angle;
float width;
};
class GGCNNHandle
{
public:
GGCNNHandle(std::string model_path);
GGCNNresults predect(cv::Mat data_in);
private:
torch::DeviceType device_type;
torch::jit::script::Module module;
cv::Mat CvtTensor2CvImg(at::Tensor in_tensor);
};
GGCNNHandle.cpp
#include "GGCNNHandle.h"
GGCNNHandle::GGCNNHandle(std::string model_path)
{
// 1. init module
device_type = torch::kCUDA;
torch::Device device(device_type);
module = torch::jit::load(model_path);
module.to(device);
module.eval();
}
GGCNNresults GGCNNHandle::predect(cv::Mat data_in)
{
cv::Mat img_input = data_in.clone();
//2. 归一化
img_input.convertTo(img_input, CV_32F);
img_input = img_input - cv::mean(img_input);
int nRows = img_input.rows;
int nCols = img_input.cols;
for (int i = 0; i < nRows; i++)
{
for (int j = 0; j < nCols; j++)
{
if (img_input.at<float>(i, j) < -1.0)
img_input.at<float>(i, j) = -1.0;
else if (img_input.at<float>(i, j) > 1.0)
img_input.at<float>(i, j) = 1.0;
}
}
// 3. cv 2 tensor
cv::Mat cv_img = img_input.clone();
auto tensor_img = torch::from_blob(cv_img.data, { 1, cv_img.rows, cv_img.cols, cv_img.channels() }).to(device_type);
tensor_img = tensor_img.permute({ 0,3,1,2 }).contiguous(); // BHWC -> BCHW
// 4. inference
std::vector<torch::jit::IValue> inputs;
inputs.emplace_back(tensor_img.to(device_type));
torch::jit::IValue output = module.forward(inputs);
auto pos_out = output.toTuple()->elements()[0].toTensor();
auto cos_out = output.toTuple()->elements()[1].toTensor();
auto sin_out = output.toTuple()->elements()[2].toTensor();
auto wid_out = output.toTuple()->elements()[3].toTensor();
pos_out = torch::sigmoid(pos_out);
cos_out = torch::sigmoid(cos_out);
sin_out = torch::sigmoid(sin_out);
wid_out = torch::sigmoid(wid_out);
// 5. postprocessing
cv::Mat q_img = CvtTensor2CvImg(pos_out);
auto cos_img = cos_out * 2 - 1;
auto sin_img = sin_out * 2 - 1;
cv::Mat ang_img = CvtTensor2CvImg(torch::atan2(sin_img, cos_img) / 2.0);
cv::Mat width_img = CvtTensor2CvImg(wid_out) * 200;
cv::GaussianBlur(q_img, q_img, cv::Size(11, 11), 2);
cv::GaussianBlur(ang_img, ang_img, cv::Size(11, 11), 2);
cv::GaussianBlur(width_img, width_img, cv::Size(11, 11), 2);
cv::Point maxLoc;
double maxValue;
cv::minMaxLoc(q_img, NULL, &maxValue, NULL, &maxLoc);
float angle = ang_img.at<float>(maxLoc) + 2 * 3.1415926;
while (angle >= 3.1415926)
{
angle -= 3.1415926;
}
float width = width_img.at<float>(maxLoc);
GGCNNresults results;
results.p = maxLoc;
results.angle = angle;
results.width = width;
return results;
}
cv::Mat GGCNNHandle::CvtTensor2CvImg(at::Tensor in_tensor)
{
//sequeeze trans tensor shape from 1*C*H*W to C*H*W
//permute C*H*W to H*W*C
//in_tensor = in_tensor.squeeze().detach().permute({ 1, 2, 0 });
in_tensor = in_tensor.squeeze().detach();
c10::IntArrayRef tsize = in_tensor.sizes();
//std::cout << "tsize: " << tsize << std::endl;
int rows = tsize[0];
int cols = tsize[1];
//see tip3,tip4
//in_tensor = in_tensor.mul(255).clamp(0, 255).to(torch::kU8);
in_tensor = in_tensor.to(torch::kCPU);
cv::Mat resultImg(rows, cols, CV_32F);
//copy the data from out_tensor to resultImg
std::memcpy((void*)resultImg.data, in_tensor.data_ptr(), sizeof(float) * in_tensor.numel());
return resultImg;
}
调用 GGCNNHandle,实现抓取位姿计算
GGCNN.cpp
// GGCNN.cpp : 此文件包含 "main" 函数。程序执行将在此处开始并结束。
//
#include "GGCNNHandle.h"
int main()
{
GGCNNHandle m_ggcnn("./model/ggcnn.pt");
while (true)
{
// 2. load img input
cv::Mat img = cv::imread("./imgs/0d.tiff", -1);
cv::Mat img_input = img.clone();
//std::cout << "col: " << img_input.cols << std::endl;
// --- cut img
int size_in = 300;
int crop_x1 = int((img_input.cols - size_in) / 2);
int crop_y1 = int((img_input.rows - size_in) / 2);
cv::Mat img_cut = img_input(cv::Rect(crop_x1, crop_y1, size_in, size_in));
cv::imshow("img_cut", img_cut);
cv::waitKey();
GGCNNresults results = m_ggcnn.predect(img_cut);
std::cout << "results: " << results.p << std::endl;
// draw
cv::Mat img_r = cv::imread("./imgs/0r.png", -1);
float width = results.width / 2;
double k = tan(results.angle);
int dx, dy;
if (0 == k)
{
dx = int(width);
dy = 0;
}
else
{
dx = int(k / abs(k) * width / pow(k * k + 1, 0.5));
dy = int(k * dx);
}
cv::Point catch_p = results.p;
int row = catch_p.y + crop_y1;
int col = catch_p.x + crop_x1;
cv::Point p1(int(col + dx), int(row - dy));
cv::Point p2(int(col - dx), int(row + dy));
cv::line(img_r, p1, p2, cv::Scalar(0, 0, 255), 1);
cv::imshow("img_r", img_r);
cv::waitKey(0);
break;
}
cv::destroyAllWindows();
}
基于上述代码程序对输入图像进行平面抓取位姿计算的结果如图4.3所示,其中红线中心为抓取中心点,红线与水平线的夹角为抓取旋转角,红线长度为夹爪张开宽度

图4.3 平面抓取预测结果
五. 基于YOLO和GGCNN的平面抓取
基于上述步骤,实现YOLO和GGCNN的平面抓取,代码如下
Grasp2D.cpp
// Grasp2D.cpp : 此文件包含 "main" 函数。程序执行将在此处开始并结束。
//
#include <iostream>
#include "YOLOv5Handle.h"
#include "GGCNNHandle.h"
int main()
{
std::vector<std::string> m_class = { "hammer","plier","adjustable_spanner","tapeline","screwdriver","hex_wrench","spanner","scissor" };
;
cv::Mat img_rgb = cv::imread("./images/RGB/47.bmp",-1);
cv::Mat img_depth = cv::imread("./images/depth/47.tiff", -1);
YOLOv5Handle m_yolo("./models/YOLOv5.torchscript");
GGCNNHandle m_ggcnn("./models/ggcnn.pt");
// YOLO
std::vector<std::vector<Detection>> result_detect = m_yolo.predect(img_rgb);
for (int i = 0; i < result_detect.size(); i++)
{
std::vector<Detection> res = result_detect[i];
for (int j = 0; j < res.size(); j++)
{
Detection det = res[j];
int res_class = det.class_idx;
if (res_class > 7)
{
std::cerr << "YOLO result class out of range" << std::endl;
return 0;
}
// GGCNN
//std::cout << "bbox: " << det.bbox << std::endl;
cv::Mat img_cut = img_depth(det.bbox).clone();
cv::resize(img_cut, img_cut, cv::Size(300, 300));
GGCNNresults result_ggcnn = m_ggcnn.predect(img_cut);
//std::cout << "result_ggcnn P: "<< result_ggcnn.p <<std::endl;
float width = result_ggcnn.width / 2;
double k = tan(result_ggcnn.angle);
int dx, dy;
if (0 == k)
{
dx = int(width);
dy = 0;
}
else
{
dx = int(k / abs(k) * width / pow(k * k + 1, 0.5));
dy = int(k * dx);
}
//std::cout << "dx: " << dx << " dy: " << dy << std::endl;
double k_width = double(det.bbox.width) / 300.0;
double k_height = double(det.bbox.height) / 300.0;
//std::cout << "k_width: " << k_width << " k_height: " << k_height << std::endl;
int col = int(result_ggcnn.p.x * k_width) + det.bbox.x;
int row = int(result_ggcnn.p.y* k_height) + det.bbox.y;
//std::cout << "col: " << col << " row: " << row << std::endl;
dx = dx * k_width;
dy = dy * k_height;
cv::Point p1(int(col + dx), int(row - dy));
cv::Point p2(int(col - dx), int(row + dy));
//std::cout << "p1: " << p1 << " p2: " << p2 << std::endl;
double grasp_angle = atan(double(dy) / double(dx))*180/3.1415926;
double grasp_width = pow((dx * dx) + (dy * dy), 0.5) * 2;
std::cout << "grasp " << m_class[res_class] << ", center point ( " << col << ", " << row << "), angle: " << grasp_angle << ", width: " << grasp_width << std::endl;
// draw
int c_r = res_class * 100 > 512 ? 255 : 0;
int c_g = res_class * 100 > 255 ? 255 : 0;
int c_b = (res_class * 100) % 255;
cv::Scalar m_c(c_b, c_g, c_r);
cv::rectangle(img_rgb, det.bbox, m_c,1);
cv::putText(img_rgb, m_class[res_class], cv::Point(det.bbox.x, det.bbox.y), cv::FONT_HERSHEY_SIMPLEX, 1, m_c,2);
cv::line(img_rgb, p1, p2, m_c, 3);
}
}
cv::imshow("img_rgb", img_rgb);
cv::waitKey(0);
cv::destroyAllWindows();
}
基于上述代码程序,计算得到的平面抓取位姿结果如图5.1所示
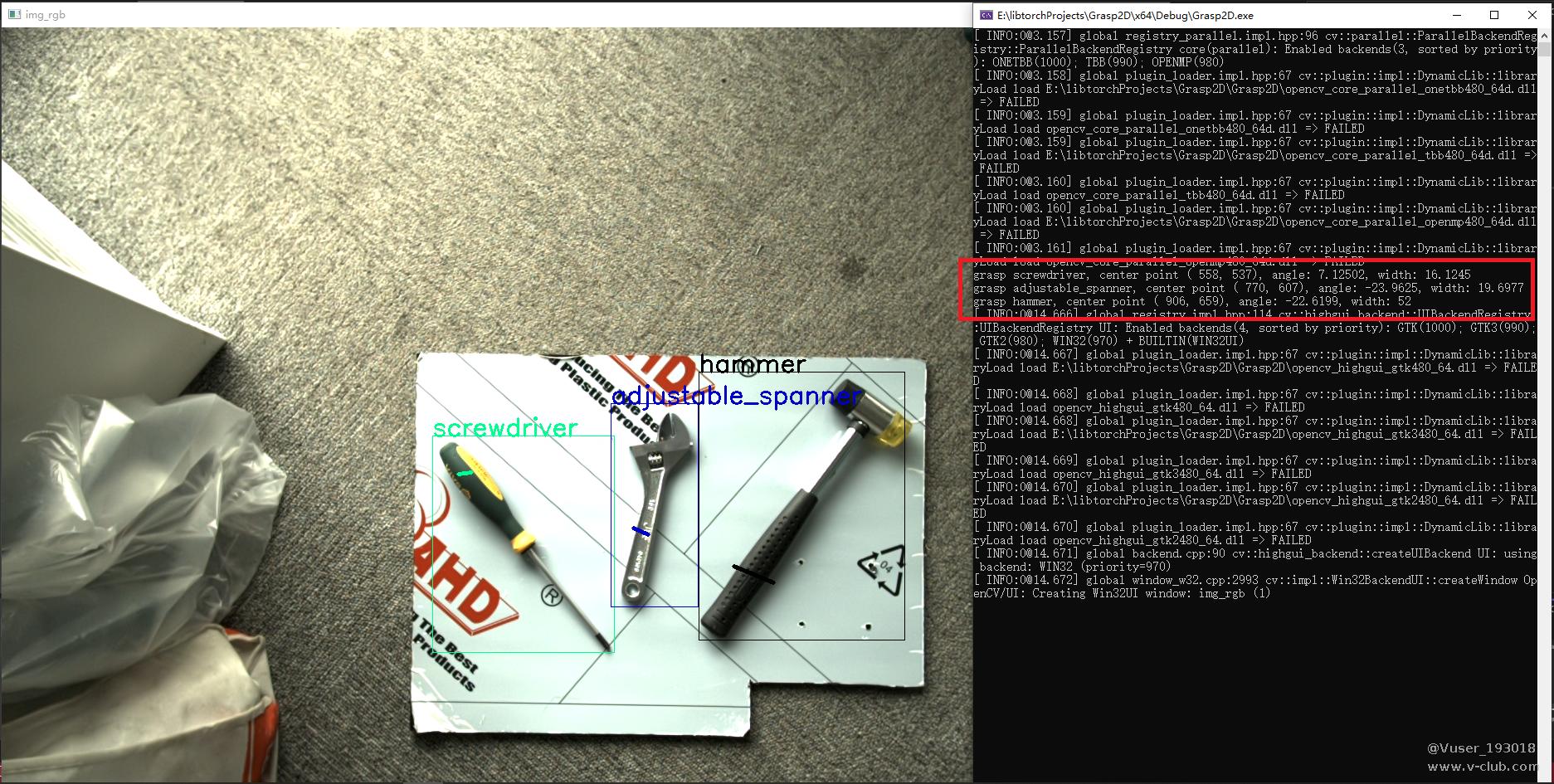
图5.1 平面抓取结果










 浙公网安备 33010802013223号
浙公网安备 33010802013223号