- 0
- 0
- 分享
- 2024-10-28 10:52
研究背景以及基本的环境部分请见:第三届‘悉灵杯’-基于MV-EB435i-A相机的室内3D语义感知课题研究进展(一)
数据处理部分请见:第三届‘悉灵杯’-基于MV-EB435i-A相机的室内3D语义感知课题研究进展(二)
模型部分
首先使用scenenn数据集和scannet的预训练模型进行测试,基于xuxw98/ESAM: EmbodiedSAM: Online Segment Any 3D Thing in Real Time (github.com)进行开发。
离线方法在一些实时决策场景并不适用。而实时在线运行时,未来帧不可用,且对象在连续帧中重复出现,需要帧间对象匹配,计算复杂度较高。

如图,使用3D感知查询模块,通过快速查询将2D掩码投影到3D点云,并迭代细化;在帧间对象匹配时计算不同视图3D掩码相似度矩阵进行多视角匹配,提高3D感知精度。将SAM生成的2D掩码视为超点,用于由我们提出的几何感知池化模块指导掩码聚合,生成与SAM掩码一一对应的3D查询。
运行下面命令采集处理好微调数据:
cd /f/pro/Hik/code/sensing3D
cd SDK_Mv3DRgbd_V1.3.0.4_Linux_240507/SAMple/Python/
sudo ./set_usbfs_memory_size.sh
python get_data.py
python get_pose.py
python get_point.py
python register_points.py
得到的数据用预训练模型得到分割伪标签后用CloudCompare进行标注,在mmdet3D的config中使用backbone=dict(frozen_stages=4)进行冻结后微调MergingHead。下一步就是使用摄像头实时分割。
运行hik_demo.py代码如下:
import os
import subprocess
def run_commands():
try:
# Set the environment variable
os.environ['OMP_NUM_THREADS'] = '24'
while True:
# Execute the series of commands
os.chdir('/f/pro/Hik/code/sensing3D/SDK_Mv3DRgbd_V1.3.0.4_Linux_240507/SAMple/Python/')
subprocess.run(['python', 'get_data.py'])
os.chdir('/f/pro/Hik/code/sensing3D/data/hiknn-mv')
subprocess.run(['python', 'load_hik_mv_data_fast.py'])
os.chdir('/f/pro/Hik/code/sensing3D')
subprocess.run(['python', 'tools/create_data.py', 'hiknn_mv', '--root-path', 'data/hiknn-mv', '--out-dir', './data/hiknn-mv', '--extra-tag', 'hiknn_mv'])
subprocess.run(['python', 'vis_demo/hik_demo.py',
'--scene_idx', '00',
'--config', 'configs/hik_demo.py',
'--checkpoint', 'work_dirs/tmp/ESAM-E_CA_online_epoch_128.pth'])
except KeyboardInterrupt:
print("\nExecution halted by user.")
run_commands()
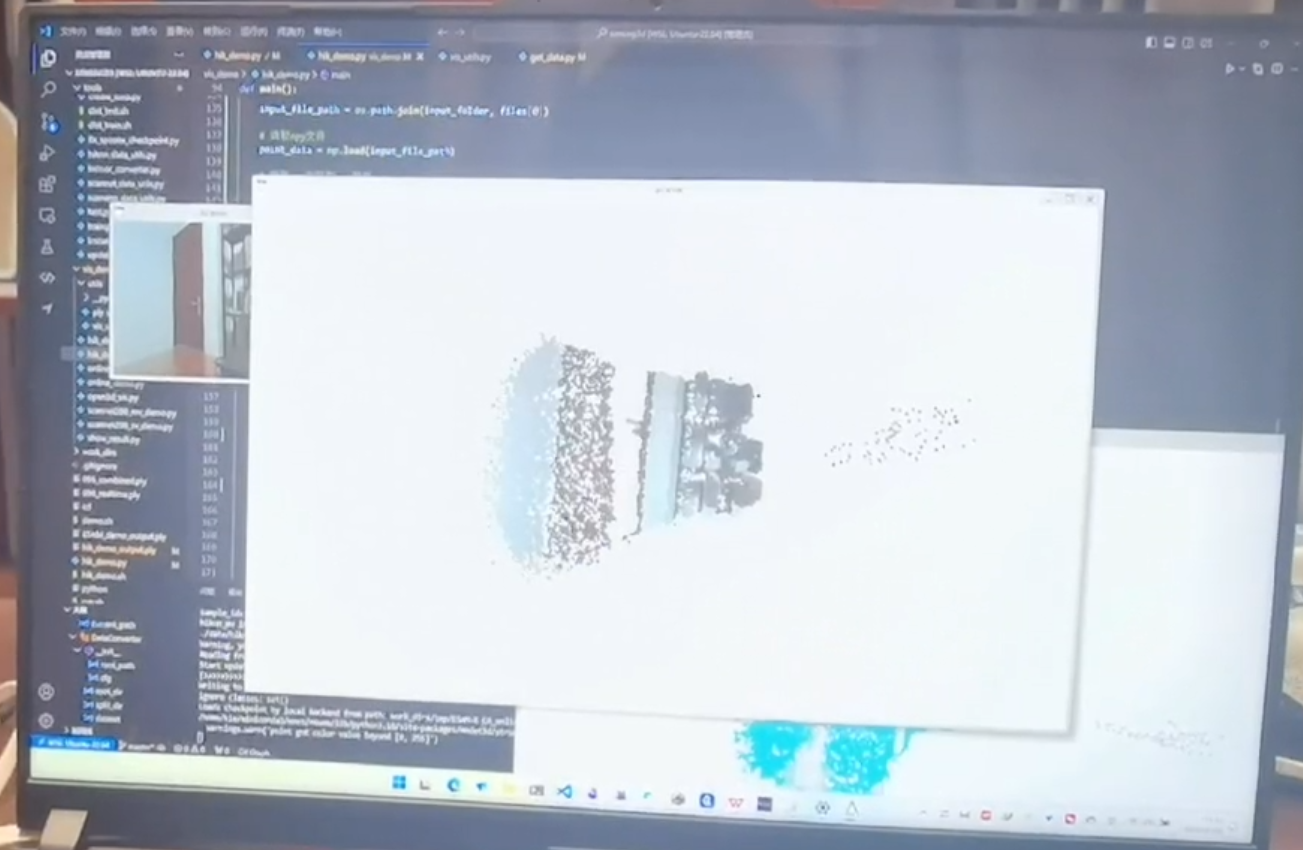
运行结果
前一部分运行结果请见附件。测试环境为室内单视角推理结果。可以看出模型总体前景和背景分割出来了,但是细节部分还可以优化,后续考虑使用更精细的重建方法;最终的推理速度实测也未达到10fps,多视角连续帧计算是本次研究可以优化的方向,后续考虑用PTQ后量化以及TensorRT进行算子融合加速。
总结展望
本次学习也是第一次接触RGB-D摄像机,感谢海康提供的这次机会让我有条件对3D视觉方面进行实践,学习到了如何正确处理自己采集的3D深度图像、RGB图像以及对应的点云数据;并且在此过程中,学习了3D感知相关最新的算法模型原理;中间遇到的各种困难和bug,我们小队通过查阅海康官方资料、参考v社区的经验、自己一行一行深入模型debug出问题,最终也是成功的完成了模型语义感知推理。
如运行结果所示,我们在完成一个阶段后也进行了反思,仍旧有许多问题值得继续深入思考与优化。有机会希望能向海康的各位大咖继续交流学习,进一步提升技术水平,为未来的3D视觉研究贡献更多的力量。



 话术-用AI协助编写VM3D脚本模块的代码2026-06-29
话术-用AI协助编写VM3D脚本模块的代码2026-06-29 基于基础应用扩展的偏心抓取算法2026-07-07
基于基础应用扩展的偏心抓取算法2026-07-07 更换主控具体需要准备哪些工具和文件?2026-07-23
更换主控具体需要准备哪些工具和文件?2026-07-23- 移动机器人技术分享-26年7月2026-07-17
 浙公网安备 33010802013223号
浙公网安备 33010802013223号